8 Causal inference with G-computation
Randomized experiments are often considered the gold standard research design for causal inference. Assigning individuals to different treatments at random ensures that, on average and under ideal conditions, the groups we compare have similar background characteristics. This overall similarity gives us more confidence that any differences to emerge between groups are caused by the treatments of interest. Randomized experiments are powerful tools but, unfortunately, they are often impractical or unethical. In such cases, we must turn to observational data.
Drawing causal inference from observational data can be difficult. Often, factors beyond the analyst’s control influence both the exposure to treatment and the outcome of interest. Such confounding variables can introduce bias in our estimates of the treatment effect.
Imagine a study designed to assess the effect of daily vitamin D supplementation on bone density. If an analyst finds that individuals taking vitamin D have higher bone density, they may be tempted to conclude that supplementation directly enhances bone health. However, people who choose to take vitamin D might also be more health-conscious and engage in other bone-strengthening activities, such as exercising or eating calcium-rich foods. These confounding factors can obscure the true causal effect. They can introduce bias in the analyst’s estimates.
G-computation1 is a method developed to draw causal inference from observational data. The idea is simple. First, we fit a statistical model which controls for confounders. Then, we use the fitted model to “predict” or “impute” what would happen to an individual under alternative treatment scenarios. Finally, we compare counterfactual predictions to derive an estimate of the treatment effect (Hernán and Robins 2020).
As we will see below, G-computation estimates are equivalent to the counterfactual predictions and comparisons discussed in Chapters 5 and 6. They are also closely related to the estimates we can obtain by Inverse Probability Weighting (IPW), another popular causal inference tool. IPW and G-computation impose similar identification assumptions, with one key difference: the former models the process that determines who gets treated, whereas the latter models the outcome variable.2
The next section introduces some key estimands that analysts can target via G-computation: the average treatment effect (ATE), average treatment effect on the treated (ATT), and average treatment effect on the untreated (ATU). Subsequent sections present the estimation procedure as a sequence of three steps: model, impute, and compare.
8.1 Treatment effects: ATE, ATT, ATU
Our goal is to estimate the effect of a treatment \(D\) on an outcome \(Y\). To express this effect as a formal estimand, and to understand the assumptions required to target that estimand, we need to introduce a bit of notation from the potential outcomes tradition of causal inference.3
The first term we need to define represents the value of the treatment, or explanatory variable. When \(D_i=1\), the individual \(i\) is assigned to the treatment group. When \(D_i=0\), \(i\) is part of the control group.
The second term represents the outcome variable. Here, it is essential to draw a distinction between the actual value of the outcome, and its potential values. The actual outcome is what we observe for individual \(i\) in our dataset: \(Y_i\). In contrast, the potential outcomes are written with superscripts: \(Y_i^0\) and \(Y_i^1\). They represent the outcomes that would occur in counterfactual worlds where \(i\) receives different treatments. \(Y_i^0\) is the value of the outcome in a hypothetical world where \(i\) belongs to the control group. \(Y_i^1\) is the value of the outcome in a hypothetical world where \(i\) belongs to the treatment group. Crucially, only one potential outcome can ever be observed at any given time, for any given individual. Since \(i\) cannot be part of both the treatment and control groups simultaneously, we can never measure the values of both \(Y_i^1\) and \(Y_i^0\). We can only measure the potential outcome that corresponds to the treatment actually assigned to individual \(i\).
The ambitious analyst would love to estimate the Individual Treatment Effect (ITE), defined as the difference between outcomes for \(i\) under different treatment regimes: \(Y_i^1-Y_i^0\). Unfortunately, since we can only observe one of the two potential outcomes, the ITE is impossible to compute. This is what some have called the fundamental problem of causal inference.
To circumvent this problem, we turn away from individual-level estimands, and consider three aggregated quantities of interest: ATE, ATT, and ATU. These three quantities are related, but they invite different interpretations and impose different assumptions (Greifer and Stuart 2021).
8.1.1 Interpretation
Our three estimands are defined as follows:
\[\begin{align*} E[Y_i^1 - Y_i^0] && \mbox{(ATE)} \\ E[Y_i^1 - Y_i^0|D_i=1] && \mbox{(ATT)} \\ E[Y_i^1 - Y_i^0|D_i=0] && \mbox{(ATU)} \end{align*}\]
The ATE estimates the average effect of the treatment on the outcome in the entire study population. The ATE helps us answer this question: Should a program or treatment be implemented universally?
The ATT estimates the average effect of the treatment on the outcome in the subset of study participants who actually received it. The ATT helps us answer this question: Should a program or treatment be withheld from the people currently receiving it?
The ATU estimates the average effect of the treatment on the subgroup of participants who did not, in fact, get it. The ATU helps us answer this question: Should a program or treatment be extended to those who did not initially receive it?
8.1.2 Assumptions
Estimating the ATE, ATT, or ATU requires us to accept four assumptions, with varying levels of stringency (Greifer and Stuart 2021; Chatton and Rohrer 2024).
First, conditional exchangeability or no unmeasured confounding. This assumption states that potential outcomes must be independent of treatment assignment, conditional on a set of control variables (\(Z_i\)). More formally, we can write \(Y_i^1,Y_i^0 \perp D_i \mid Z_i\).
Imagine a person who considers entering a training program designed to improve their likelihood of finding a job. If that person knows they will be employed regardless of whether they receive training, then they are unlikely to enroll in the program: if \(Y_i^1=Y_i^0\), then \(D_i=0\). Similarly, imagine a doctor who recommends a certain medication only to the patients who are most likely to benefit from it: if \(Y_i^1>Y_i^0\), then \(D_i=1\). In both cases, potential outcomes are linked to the treatment assignment mechanism: \(D_i \not\perp Y_i^1,Y_i^0\). In both cases, the conditional exchangeability assumption is violated, unless the analyst can control for all relevant confounders.
When estimating the ATE, conditional exchangeability must hold across the entire population. When estimating the ATT, however, this stringent assumption can be relaxed somewhat. The intuition is straightforward: since the ATT is computed solely based on units in the treatment group, we can observe all instances of the \(Y_i^1\) potential outcomes. Thus, to estimate the ATT, we only need to make assumptions about the unobserved \(Y_i^0\) potential outcomes; we only need to adjust for confounders that link treatment assignment to participants’ outcomes under the control condition. Analogously, estimating the ATU only requires conditional exchangeability to hold in the treatment condition.
Second, positivity. This assumption requires study participants to have a non-zero probability of belonging to each treatment arm: \(0<P(D_i=1\mid Z_i)<1\). In practice, this condition can be violated for a number of reasons, such as when certain individuals fail to meet eligibility criteria to receive a certain treatment, but are still part of the control group.
When we estimate the ATE, positivity must hold across the entire sample. However, when we estimate the ATT, the positivity assumption can be relaxed somewhat: \(P(D_i=1|Z_i)<1\). This new condition means that no participant can be certain to receive the treatment, but that some participants can be ruled ineligible. Analogously, we can estimate the ATU by accepting a weaker form of positivity, where every participant must have some chance to be treated: \(P(D_i=1|Z_i)>0\).
Third, consistency.4 This assumption requires the intervention to be well-defined; there must be no ambiguity about what constitutes “treatment” and “control.” For example, in a medical study, consistency may require that all participants in the treatment group be administered the same drug, under the same conditions, with the same dosage. In the context of a job training intervention, consistency might require strict adherence to a specific program design, with fixed hours of in-person teaching, number of assignments, internship requirements, etc.
Fourth, non-interference. This final assumption says that potential outcomes for one participant should not be affected by the treatment assignments of other individuals. Assigning one person (or group) to a treatment regime cannot lead to contagion or generate externalities for other participants in the study.
When these four assumptions hold, we can estimate the effect of a treatment via G-computation. The remainder of this section describes this estimation strategy as a series of three steps: model, impute, and compare.
8.1.3 Model
To illustrate how to estimate the ATE, ATT, and ATU using G-computation, let us consider this study by Imbens et al. (2001): Estimating the Effect of Unearned Income on Labor Earnings, Savings, and Consumption: Evidence from a Survey of Lottery Players. In that article, the authors conducted a survey to estimate the effect of winning large lottery prizes on economic behavior. They studied a range of outcomes for different subgroups of the population. This chapter focuses on the effect of winning a big lottery prize on labor earnings.
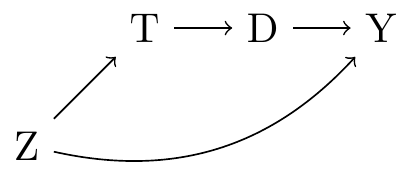
The treatment is a binary variable equal to one if an individual won a big lottery prize, and zero otherwise (\(D\)). The outcome is the average labor earnings over the subsequent six years (\(Y\)). Winning lottery numbers are chosen randomly, but the probability that any given person wins a prize is not purely random: it depends on how many tickets that person bought (\(L\)). Finally, we know that socio-demographic characteristics (\(Z\)) like age, education, and employment status, can influence both the number of tickets that a person buys and their labor earnings. These causal relationships are illustrated in the graph below.
Imbens et al. (2001) collected survey responses to measure the variables in this graph. Their dataset includes a variety of information about 437 respondents, including 194 who won small lottery prizes, and 43 who won big prizes. For simplicity, we will only compare individuals who won a big prize to those who won nothing at all.
library(marginaleffects)
dat = get_dataset("lottery")
dat = subset(dat, win_big == 1 | win == 0)
head(dat, n = 2) age college education man prize tickets win win_big win_small work year
1 76 0 12 0 0 2 0 0 0 0 1986
3 59 1 16 1 0 2 0 0 0 1 1986
earnings_pre_avg earnings_post_avg earnings_pre_1 earnings_pre_2
1 0.00000 0.00000 0.00000 0.0000
3 35.68592 22.83054 34.44951 35.8099
earnings_pre_3 earnings_pre_4 earnings_pre_5 earnings_pre_6 earnings_post_1
1 0.00000 0.00000 0.00000 0.00000 0.000
3 36.79834 39.28434 39.87372 40.33606 42.258
earnings_post_2 earnings_post_3 earnings_post_4 earnings_post_5
1 0.00000 0.00000 0.00000 0
3 42.25775 41.69062 33.60743 0
earnings_post_6 earnings_post_7
1 0 0
3 0 0import polars as pl
import numpy as np
from marginaleffects import *
from statsmodels.formula.api import logit, ols
dat = get_dataset("lottery")
dat = dat.filter((pl.col('win_big') == 1) | (pl.col('win') == 0))
dat.head()
shape: (5, 26)
| age | college | education | man | prize | tickets | win | win_big | win_small | work | year | earnings_pre_avg | earnings_post_avg | earnings_pre_1 | earnings_pre_2 | earnings_pre_3 | earnings_pre_4 | earnings_pre_5 | earnings_pre_6 | earnings_post_1 | earnings_post_2 | earnings_post_3 | earnings_post_4 | earnings_post_5 | earnings_post_6 | earnings_post_7 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 |
| 76.0 | 0.0 | 12.0 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1986.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 59.0 | 1.0 | 16.0 | 1.0 | 0.0 | 2.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1986.0 | 35.685919 | 22.830541 | 34.449515 | 35.809901 | 36.798342 | 39.284337 | 39.873725 | 40.336059 | 42.258 | 42.257746 | 41.690617 | 33.607426 | 0.0 | 0.0 | 0.0 |
| 60.0 | 0.0 | 9.0 | 1.0 | 106.053559 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 1984.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 59.0 | 1.0 | 16.0 | 1.0 | 0.0 | 2.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1987.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 45.0 | 0.0 | 14.0 | 1.0 | 137.271838 | 0.0 | 1.0 | 1.0 | 0.0 | 1.0 | 1984.0 | 25.451963 | 41.265647 | 23.97584 | 25.226116 | 27.153932 | 26.224422 | 26.133637 | 30.283052 | 37.131088 | 40.336059 | 42.0 | 42.257746 | 41.690617 | 42.425806 | 43.01821 |
The first G-computation step is to define an outcome equation, that is, to specify a parametric regression model for the dependent variable. The primary goal of this regression model is to control for confounders, that is, to ensure that we satisfy the conditional exchangeability assumption.
As noted above, the process that determines which lottery tickets are winning is purely random, but the probability that any given individual wins depends on the number of tickets they bought. This means that the treatment assignment (\(D\)) is not completely independent from the potential outcomes (\(Y_i^1,Y_i^0\)). To satisfy the conditional exchangeability assumption,5 our statistical model must control for the number of tickets (\(L\)) that each survey respondents bought and/or for all the \(Z\) covariates that link \(D\) to \(Y\).
This regression model can be simple or flexible. It can be purely linear, or include a non-linear link function, multiplicative interactions, polynomials, or splines.6 The model can satisfy the conditional exchangeability assumption using a minimal set of control variables (\(L\)), or it can include more covariates (\(Z\)) to improve precision.7
Here, we fit a linear regression where the treatment variable (win_big) is interacted with the number of tickets bought (tickets) and a series of demographic characteristics, including gender, age, employment, and pre-lottery labor earnings. To interact treatment and covariates, we insert a star * symbol and parentheses in the regression formula.
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1302.25641 1099.91390 1.184 0.2374
win_big 1327.56843 2435.94389 0.545 0.5862
tickets 0.13340 0.31632 0.422 0.6736
man -0.85082 1.27346 -0.668 0.5046
work 3.24753 1.61780 2.007 0.0457
age -0.23762 0.05330 -4.459 <0.001
education -0.53448 0.53047 -1.008 0.3145
college 3.03770 2.08575 1.456 0.1464
year -0.64566 0.55434 -1.165 0.2451
earnings_pre_1 0.05247 0.16390 0.320 0.7491
earnings_pre_2 -0.04408 0.18013 -0.245 0.8069
earnings_pre_3 0.86314 0.10288 8.390 <0.001
win_big:tickets -0.17277 0.54143 -0.319 0.7499
win_big:man 1.51214 4.38811 0.345 0.7307
win_big:work -0.73710 5.23892 -0.141 0.8882
win_big:age 0.13777 0.14432 0.955 0.3406
win_big:education 0.61646 1.11628 0.552 0.5812
win_big:college 9.62742 5.50191 1.750 0.0812
win_big:year -0.67657 1.22789 -0.551 0.5821
win_big:earnings_pre_1 -0.23283 0.41698 -0.558 0.5770
win_big:earnings_pre_2 -0.26659 0.49941 -0.534 0.5939
win_big:earnings_pre_3 -0.12319 0.27092 -0.455 0.6497f = """
earnings_post_avg ~ win_big * (
tickets + man + work + age + education + college + year +
earnings_pre_1 + earnings_pre_2 + earnings_pre_3)
"""
mod = ols(f, data=dat).fit()
mod.summary()| Dep. Variable: | earnings_post_avg | R-squared: | 0.743 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.724 |
| Method: | Least Squares | F-statistic: | 38.63 |
| Date: | Mon, 13 Jul 2026 | Prob (F-statistic): | 3.71e-70 |
| Time: | 11:30:22 | Log-Likelihood: | -1074.5 |
| No. Observations: | 302 | AIC: | 2193. |
| Df Residuals: | 280 | BIC: | 2275. |
| Df Model: | 21 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 1302.2564 | 1099.914 | 1.184 | 0.237 | -862.894 | 3467.407 |
| win_big | 1327.5684 | 2435.944 | 0.545 | 0.586 | -3467.520 | 6122.657 |
| tickets | 0.1334 | 0.316 | 0.422 | 0.674 | -0.489 | 0.756 |
| man | -0.8508 | 1.273 | -0.668 | 0.505 | -3.358 | 1.656 |
| work | 3.2475 | 1.618 | 2.007 | 0.046 | 0.063 | 6.432 |
| age | -0.2376 | 0.053 | -4.459 | 0.000 | -0.343 | -0.133 |
| education | -0.5345 | 0.530 | -1.008 | 0.315 | -1.579 | 0.510 |
| college | 3.0377 | 2.086 | 1.456 | 0.146 | -1.068 | 7.143 |
| year | -0.6457 | 0.554 | -1.165 | 0.245 | -1.737 | 0.446 |
| earnings_pre_1 | 0.0525 | 0.164 | 0.320 | 0.749 | -0.270 | 0.375 |
| earnings_pre_2 | -0.0441 | 0.180 | -0.245 | 0.807 | -0.399 | 0.311 |
| earnings_pre_3 | 0.8631 | 0.103 | 8.390 | 0.000 | 0.661 | 1.066 |
| win_big:tickets | -0.1728 | 0.541 | -0.319 | 0.750 | -1.239 | 0.893 |
| win_big:man | 1.5121 | 4.388 | 0.345 | 0.731 | -7.126 | 10.150 |
| win_big:work | -0.7371 | 5.239 | -0.141 | 0.888 | -11.050 | 9.576 |
| win_big:age | 0.1378 | 0.144 | 0.955 | 0.341 | -0.146 | 0.422 |
| win_big:education | 0.6165 | 1.116 | 0.552 | 0.581 | -1.581 | 2.814 |
| win_big:college | 9.6274 | 5.502 | 1.750 | 0.081 | -1.203 | 20.458 |
| win_big:year | -0.6766 | 1.228 | -0.551 | 0.582 | -3.094 | 1.741 |
| win_big:earnings_pre_1 | -0.2328 | 0.417 | -0.558 | 0.577 | -1.054 | 0.588 |
| win_big:earnings_pre_2 | -0.2666 | 0.499 | -0.534 | 0.594 | -1.250 | 0.716 |
| win_big:earnings_pre_3 | -0.1232 | 0.271 | -0.455 | 0.650 | -0.656 | 0.410 |
| Omnibus: | 8.005 | Durbin-Watson: | 1.942 |
|---|---|---|---|
| Prob(Omnibus): | 0.018 | Jarque-Bera (JB): | 13.214 |
| Skew: | -0.081 | Prob(JB): | 0.00135 |
| Kurtosis: | 4.012 | Cond. No. | 9.88e+06 |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 9.88e+06. This might indicate that there are
strong multicollinearity or other numerical problems.
8.1.4 Impute
The second G-computation step is to impute—or predict—the outcome for each observed individual, under different hypothetical treatment regimes. To do this, we create two identical copies of the dataset used to fit the model, and we use the transform function to fix the win_big variable to counterfactual values.
Using these two datasets, we predict the expected earnings_post_avg for each participant under counterfactual treatment regimes.
p0 = predictions(mod, newdata = d0)
p1 = predictions(mod, newdata = d1)p0 = predictions(mod, newdata = d0)
p1 = predictions(mod, newdata = d1)To take stock of what we have done so far, we can inspect the original dataset, and compare the predicted outcomes for an arbitrary survey respondent: the person in the sixth row of our dataset. By subsetting the data frame, we see that this person did not, in fact, win a big lottery prize.
dat[6, "win_big"][1] 0dat[5, 'win_big']0.0Using our fitted model, we predicted that this person’s average labor earnings—without lottery winnings—would be:
p0[6, "estimate"][1] 31.91696p0[5, 'estimate']31.916959779438518If this individual belonged to the treatment group instead (win_big=1), our model would predict lower earnings:
p1[6, "estimate"][1] 24.5759p1[5, 'estimate']24.57590471880588Thus, our model expects that, for an individual with these socio-demographic characteristics, winning the lottery is likely to decrease labor earnings. In the next section, we compare these predicted outcomes more systematically, at the aggregate level, to estimate the ATE, ATT, and ATU.
8.1.5 Compare
To estimate the treatment effect of win_big via G-computation, we aggregate individual-level predictions from the two counterfactual worlds. We can do this by extracting the vectors of estimates computed above and by calling the mean() function.
The average predicted outcome in the control counterfactual is:
mean(p0$estimate)[1] 17.42834p0.select('estimate').mean()shape: (1, 1)
┌──────────┐
│ Estimate │
│ --- │
│ str │
╞══════════╡
│ 17.4 │
└──────────┘The average predicted outcome in the treatment counterfactual is:
mean(p1$estimate)[1] 11.86662p1.select('estimate').mean()shape: (1, 1)
┌──────────┐
│ Estimate │
│ --- │
│ str │
╞══════════╡
│ 11.9 │
└──────────┘A more convenient way to obtain the same quantities is to call the avg_predictions() function from the marginaleffects package. As noted in Chapter 5, using the variables argument computes predicted values on a counterfactual grid, and the by argument marginalizes with respect to the focal variable. The results are the same as those we calculated manually, but they now come with standard errors and confidence intervals.
avg_predictions(mod,
variables = "win_big",
by = "win_big")| win_big | Estimate | Std. Error | z | Pr(>|z|) | 2.5 % | 97.5 % |
|---|---|---|---|---|---|---|
| 0 | 17.4283 | 0.570125 | 30.56932 | < 0.001 | 16.31092 | 18.5458 |
| 1 | 11.8666 | 2.278478 | 5.20813 | < 0.001 | 7.40089 | 16.3324 |
avg_predictions(mod, variables = "win_big", by = "win_big")shape: (2, 8)
┌─────────┬──────────┬───────────┬──────┬─────────┬──────┬──────┬───────┐
│ win_big ┆ Estimate ┆ Std.Error ┆ z ┆ P(>|z|) ┆ S ┆ 2.5% ┆ 97.5% │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ str ┆ str ┆ str ┆ str ┆ str ┆ str ┆ str │
╞═════════╪══════════╪═══════════╪══════╪═════════╪══════╪══════╪═══════╡
│ 0 ┆ 17.4 ┆ 0.57 ┆ 30.6 ┆ 0 ┆ inf ┆ 16.3 ┆ 18.6 │
│ 1 ┆ 11.9 ┆ 2.28 ┆ 5.21 ┆ 3.7e-07 ┆ 21.4 ┆ 7.38 ┆ 16.4 │
└─────────┴──────────┴───────────┴──────┴─────────┴──────┴──────┴───────┘The ATE is the difference between the two estimates printed above. We can compute it by subtraction, or use the avg_comparisons() function.
cmp = avg_comparisons(mod,
variables = "win_big",
newdata = dat)
cmp| Estimate | Std. Error | z | Pr(>|z|) | 2.5 % | 97.5 % |
|---|---|---|---|---|---|
| -5.56172 | 2.34872 | -2.36798 | 0.0178857 | -10.1651 | -0.958308 |
avg_comparisons(mod, variables = "win_big")shape: (1, 7)
┌──────────┬───────────┬───────┬─────────┬──────┬───────┬────────┐
│ Estimate ┆ Std.Error ┆ z ┆ P(>|z|) ┆ S ┆ 2.5% ┆ 97.5% │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ str ┆ str ┆ str ┆ str ┆ str ┆ str │
╞══════════╪═══════════╪═══════╪═════════╪══════╪═══════╪════════╡
│ -5.56 ┆ 2.35 ┆ -2.37 ┆ 0.0186 ┆ 5.75 ┆ -10.2 ┆ -0.938 │
└──────────┴───────────┴───────┴─────────┴──────┴───────┴────────┘
Term: win_big
Contrast: 1 - 0This is the G-computation estimate of the average treatment effect of win_big on earnings_post_avg. On average, our model estimates that moving from the loser to the winner group decreases the predicted outcome by 5.6.
To compute the ATT, we use the same approach as above, but restrict our attention to the subset of individuals who were actually treated. We use the subset() function to select rows of the original dataset with treated individuals, and feed the resulting grid to the newdata argument.
avg_comparisons(mod,
variables = "win_big",
newdata = subset(win_big == 1))| Estimate | Std. Error | z | Pr(>|z|) | 2.5 % | 97.5 % |
|---|---|---|---|---|---|
| -9.48789 | 1.82432 | -5.20078 | < 0.001 | -13.0635 | -5.91229 |
avg_comparisons(mod, variables = "win_big",
newdata=dat.filter(pl.col('win_big') == 1))shape: (1, 7)
┌──────────┬───────────┬──────┬──────────┬──────┬───────┬───────┐
│ Estimate ┆ Std.Error ┆ z ┆ P(>|z|) ┆ S ┆ 2.5% ┆ 97.5% │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ str ┆ str ┆ str ┆ str ┆ str ┆ str │
╞══════════╪═══════════╪══════╪══════════╪══════╪═══════╪═══════╡
│ -9.49 ┆ 1.82 ┆ -5.2 ┆ 3.84e-07 ┆ 21.3 ┆ -13.1 ┆ -5.9 │
└──────────┴───────────┴──────┴──────────┴──────┴───────┴───────┘
Term: win_big
Contrast: 1 - 0The ATU is computed analogously, by restricting our attention to the subset of untreated individuals.
avg_comparisons(mod,
variables = "win_big",
newdata = subset(win_big == 0))| Estimate | Std. Error | z | Pr(>|z|) | 2.5 % | 97.5 % |
|---|---|---|---|---|---|
| -4.90989 | 2.59001 | -1.8957 | 0.0579996 | -9.98622 | 0.166441 |
avg_comparisons(mod, variables = "win_big",
newdata=dat.filter(pl.col('win_big') == 0))shape: (1, 7)
┌──────────┬───────────┬──────┬─────────┬──────┬──────┬───────┐
│ Estimate ┆ Std.Error ┆ z ┆ P(>|z|) ┆ S ┆ 2.5% ┆ 97.5% │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ str ┆ str ┆ str ┆ str ┆ str ┆ str │
╞══════════╪═══════════╪══════╪═════════╪══════╪══════╪═══════╡
│ -4.91 ┆ 2.59 ┆ -1.9 ┆ 0.059 ┆ 4.08 ┆ -10 ┆ 0.188 │
└──────────┴───────────┴──────┴─────────┴──────┴──────┴───────┘
Term: win_big
Contrast: 1 - 0It is interesting to notice that the three quantities of interest are quite different from one another. Indeed, the fact that the ATT is larger than the ATU suggests an asymmetry. Our model expects a strong decrease in earnings after winning a prize for people who are more likely to win (i.e., people who buy a lot of tickets). In contrast, our model expects a smaller decrease in earnings after winning a prize for people who are less likely to win (i.e., people who buy fewer tickets). This finding underscores the importance of clearly defining one’s estimand before estimating and interpreting statistical models.8
Note that subtle issues arise when computing standard errors for G-computation estimates. In particular, standard errors calculated by assuming that covariates are fixed rather than sampled may not always have adequate coverage in the target population (Ding et al. 2023, ch.9). Many applied researchers have thus turned to the bootstrap as a simple strategy to quantify uncertainty around causal estimates (e.g., via the inferences() function from the marginaleffects package). Researchers have proposed analytic expressions for the unconditional variance (Ye et al. 2023; Hansen and Overgaard 2024; Magirr et al. 2025). Interested readers can visit the marginaleffects.com website for a discussion of alternatives and implementation details.
8.2 Conditional treatment effects: CATE
The conditional average treatment effect (CATE) is an estimand that can be used to characterize how the effect of a treatment varies across subgroups. Unlike the ATE, which provides an overall average, the CATE allows us to see if certain individuals respond differently, depending on their individual characteristics. Formally, the CATE of \(D_i\) is written
\[ E[Y_i^1 - Y_i^0 \mid X_i = x], \]
where \(Y_i^1\) is the potential outcome when the treatment \(D_i=1\), and \(Y_i^0\) is the potential outcome when the treatment \(D_i=0\). The \(X_i=x\) after the vertical bar indicates that the average treatment effect is estimated separately for specific values of the covariate \(X_i\), rather than averaged across the entire distribution of covariates. The conditioning variable \(X_i\) could represent discrete variables such as education or employment status.
To illustrate, let us estimate the effect of winning a big lottery prize on labor earnings, conditioning on employment status.
avg_comparisons(mod, variables = "win_big", by = "work")| work | Estimate | Std. Error | z | Pr(>|z|) | 2.5 % | 97.5 % |
|---|---|---|---|---|---|---|
| 0 | -0.0708498 | 4.86727 | -0.0145564 | 0.98838612 | -9.61053 | 9.46883 |
| 1 | -7.0973073 | 2.40032 | -2.9568188 | 0.00310831 | -11.80185 | -2.39277 |
avg_comparisons(mod, variables="win_big", by="work")shape: (2, 8)
┌──────┬──────────┬───────────┬─────────┬─────────┬────────┬───────┬───────┐
│ work ┆ Estimate ┆ Std.Error ┆ z ┆ P(>|z|) ┆ S ┆ 2.5% ┆ 97.5% │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ str ┆ str ┆ str ┆ str ┆ str ┆ str ┆ str │
╞══════╪══════════╪═══════════╪═════════╪═════════╪════════╪═══════╪═══════╡
│ 0 ┆ -0.0708 ┆ 4.87 ┆ -0.0146 ┆ 0.988 ┆ 0.0168 ┆ -9.65 ┆ 9.51 │
│ 1 ┆ -7.1 ┆ 2.4 ┆ -2.96 ┆ 0.00337 ┆ 8.21 ┆ -11.8 ┆ -2.37 │
└──────┴──────────┴───────────┴─────────┴─────────┴────────┴───────┴───────┘
Term: win_big
Contrast: 1 - 0For individuals who were initially unemployed (work=0), the estimated average effect of winning a big lottery prize on labor earnings is -0.07 which is close to zero and not statistically significant. In contrast, for individuals who were employed (work=1), the estimated effect is -7.1, meaning that winning a big lottery prize significantly reduces labor earnings. These results highlight that the effect of a financial windfall is not uniform. While unemployed individuals do not adjust their earnings, those who were previously employed substantially reduce their labor income, likely by working fewer hours or leaving the labor force altogether. This pattern aligns with economic theories suggesting that an unexpected increase in wealth can reduce the incentive to work, but mostly for those with an existing attachment to the labor market.
It is useful to note that CATEs can also be estimated with additional conditioning variables. All we would have to do is add more categorical variables to the by argument of the avg_comparisons() function. Doing this would paint a more fine-grained portrait, but also reduce the number of observations (and information) available in each subgroup.
In conclusion, G-computation provides a useful framework for estimating causal effects from observational data, allowing researchers to draw meaningful inferences even in the absence of randomized experiments. By modeling, imputing, and comparing potential outcomes, we can target estimands such as the ATE, ATT, ATU, and CATE, while accounting for confounding variables. This chapter has demonstrated the application of G-computation using a lottery study, highlighting its utility in real-world scenarios.
The estimation procedure described in this chapter is sometimes referred to as the “Parametric G-Formula.”↩︎
G-computation and IPW can be combined to create a “doubly-robust” estimator with useful properties. A comprehensive presentation of IPW and doubly-robust estimation lies outside the scope of this book. Interested readers can refer to the marginaleffects.com website for tutorials, and to Chatton and Rohrer (2024) for intuition and comparisons.↩︎
For a brief discussion, see Section 2.1.3. For more detailed presentations, see Imbens and Rubin (2015), Morgan and Winship (2015), Ding (2024).↩︎
Formally, if \(D_i=1\) then \(Y_i=Y_i^1\), and if \(D_i=0\) then \(Y_i=Y_i^0\). The consistency and non-interference assumptions are often stated together under the label “Stable Unit Treatment Value Assumption” or SUTVA.↩︎
In the Pearl (2009) tradition, we would say: “to satisfy the backdoor criterion.”↩︎