This chapter shows how marginaleffects can help us make sense of complex hierarchical data and draw inference from unrepresentative samples. To that end, we explore an empirical strategy called multilevel regression with poststratification (MRP).1
This MRP case study has three main objectives. First, it shows how to use marginaleffects to interpret estimates obtained by fitting multilevel regression models (aka, hierarchical, mixed effects, or random effects models). Second, it demonstrates that a consistent post-estimation workflow can be used to interpret the results of both frequentist and Bayesian models. Finally, this case study illustrates how to use poststratification to account for unrepresentative sampling.
We apply MRP to survey data collected in the United States. Our substantive goal is to estimate the level of support, in each American State, for budget cuts to police forces. This analysis follows Ornstein (2023), who compiled and studied data from the 2020 Cooperative Election Study (CES). Readers who are interested in a deeper dive into MRP, including a rich discussion of modeling choices and approaches, should refer to Ornstein’s excellent tutorial.
In our analysis, the outcome of interest is defund, a binary variable equal to 1 if a respondent supports cuts to police budgets.2 Predictors include individual-level covariates gender, race, age, and education. The dataset also records if each survey respondent has been a member of the military, and which state they live in.
The ces_survey dataset includes 3000 observations, randomly drawn from the full CES data.
state defund gender age education military
1 TX 0 Woman 70+ Some college 1
2 NJ 1 Woman 18-29 4 year 0
3 CO 0 Woman 60-69 4 year 1
4 PA 0 Man 50-59 4 year 1
5 PA 0 Woman 70+ High school 1
6 IA 1 Man 40-49 Some college 0
12.1 Multilevel models
Multilevel (or mixed effects) models are a popular strategy to study data that have a hierarchical, nested, or multilevel structure. Examples of nested data include survey respondents in different states; repeated measures made on the same subjects or on clustered observations; and students nested in classrooms, schools, districts, and states. A thorough introduction to multilevel modeling lies outside the scope of this chapter, but interested readers can refer to many great texts on the subject (Gelman and Hill 2006; Finch et al. 2019; Hodges 2021; Bürkner 2024).
The parameters of a multilevel model can be divided into two types: “fixed effects” and “random effects.” Fixed effects are parameters that are assumed to be constant across all groups in the population. Random effects, on the other hand, are parameters that are allowed to vary across groups. A major benefit of mixed effects models is that they allow variation in parameters between subsets of the data. For example, by specifying a “random intercept,” the analyst can let the baseline level of support for defund vary across US states. By including a “random coefficient” for the gender variable, they can allow the strength of association between gender and defund to vary from state to state.
Importantly, the random parameters of a mixed effects model are not completely free to vary from group to group. Instead, the model typically imposes constraints on the shape of the distribution of parameters. In effect, this regularizes parameters, allowing estimates for groups with small sample sizes to be informed by estimates for groups with larger sample sizes, and pulling extreme observations closer to the middle of the distribution. This can reduce the risk of overfitting and stabilize estimates.
12.2 Frequentist
Several software packages in R allow us to fit mixed effects models from a frequentist perspective, such as lme4(Bates et al. 2015) and glmmTMB(Brooks et al. 2017). When using one of these packages, we define models using the familiar formula syntax. The fixed components of our model are specified as we would any other predictor when fitting a linear or generalized linear model. Random effects components are specified using a special syntax with parentheses and a vertical bar.
y=x+z+(1+z|group)
The formula above indicates that y is the outcome variable; the associations between predictors x and z, and the outcome y are captured by fixed effect parameters; 1 is a random intercept which allows the baseline level of y to vary across groups; z is a random coefficient, allowing the strength of association between z and y to vary across groups; and group is the grouping variable.
To model the probability of supporting cuts to police budgets, we use the glmmTMB package and fit a logistic regression model which includes a random intercept and random gender coefficient by state.
Family: binomial ( logit )
Formula: defund ~ age + education + military + gender + (1 + gender |
state)
Data: survey
AIC BIC logLik -2*log(L) df.resid
3822.7 3918.8 -1895.3 3790.7 2984
Random effects:
Conditional model:
Groups Name Variance Std.Dev. Corr
state (Intercept) 0.004169 0.06457
genderWoman 0.001333 0.03650 1.00
Number of obs: 3000, groups: state, 48
Conditional model:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.2577928 0.2324920 -1.109 0.26751
age30-39 0.0192253 0.1256230 0.153 0.87837
age40-49 -0.7821669 0.1342192 -5.828 5.63e-09 ***
age50-59 -0.9662776 0.1278805 -7.556 4.15e-14 ***
age60-69 -1.1645794 0.1325723 -8.784 < 2e-16 ***
age70+ -1.3740248 0.1527391 -8.996 < 2e-16 ***
educationHigh school 0.0890342 0.2286540 0.389 0.69699
educationSome college 0.4157259 0.2297095 1.810 0.07033 .
education2 year 0.1891399 0.2478493 0.763 0.44539
education4 year 0.6204406 0.2294903 2.704 0.00686 **
educationPost grad 0.9882507 0.2405607 4.108 3.99e-05 ***
military 0.0003398 0.0829750 0.004 0.99673
genderWoman 0.1680639 0.0814649 2.063 0.03911 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
The signs of these estimated coefficients are interesting, but their magnitudes are somewhat difficult to interpret. As in previous chapters, we can use marginaleffects to make sense of those estimates.
To start, let’s use the predictions() function to compute the predicted probability of supporting cuts to police budgets for two hypothetical individuals: one from California and one from Alabama.3
p=predictions(mod, newdata =datagrid( state =c("CA", "AL"), gender ="Man", military =0, education ="4 year", age ="50-59"))# p
Our model predicts that a survey respondent with these demographic characteristics has a 35.3% chance of supporting funding cuts if they live in California, but a 37.2% chance if they live in Alabama.
To assess the strength of association between age and defund, we can use the avg_comparisons() function.
The age of survey respondents is strongly related to their propensity to answer “yes” on the defund question. On average, our model predicts that moving from the younger age bracket (18-29) to the older one (70+) is associated with a reduction of 31 percentage points in the probability of supporting cuts to police staff.
This brief example shows that we can apply the workflow described in earlier chapters to interpret the results of mixed effects models. In the next section, we analyze a similar model from a Bayesian perspective.
12.3 Bayesian
Bayesian regression analysis has a long history in statistics. Recent developments in computing, algorithm design, and software development have dramatically lowered the barriers to entry; they have made it much easier for analysts to estimate Bayesian mixed effects models.4
A typical Bayesian analysis involves several (often iterative) steps, including model formulation, prior specification, model refinement, estimation, and interpretation. Together, these steps form a “Bayesian workflow” that allows analysts to go from data to insight (Gelman et al. 2020).
This section illustrates how to use the brms package for R to fit Bayesian mixed effects models, and how the marginaleffects package facilitates two important steps of the Bayesian workflow: prior predictive checks and posterior summaries.
The model that we consider here has the same basic structure as the frequentist model from the previous section.
The age, education, and military variables are associated to fixed effect parameters, while the gender and intercept parameters are allowed to vary from state to state.
12.3.1 Prior predictive checks
One important difference between Bayesian and frequentist analysts, is that the former must explicitly specify priors over the parameters of their models. Priors encode the knowledge, beliefs, or information that the analyst held about the parameters of interest, before looking at the data. Some priors can have an important impact on the results, so it is crucial to choose them carefully.
Using the prior function from the brms package for R, we can easily specify different priors. For example, if there is a lot of uncertainty about the value of the parameters in our model, we can set “vague” or “diffuse” priors, say from a normal distribution with a large variance.
In contrast, if the analyst is confident that the parameters should be closer to zero, they can choose a more “informative” or “narrow” prior.
priors_informative=c(prior(normal(0, 0.2), class ="b"),prior(normal(0, 0.2), class ="Intercept"))
For many analysts, choosing priors is a difficult exercise. Part of this difficulty is linked to the fact that we are often required to specify priors for parameters that are expressed on an unintuitive scale.5 What do the coefficients of a mixed-effect logit model mean, and does it make sense to think that they are distributed normally with a variance of 0.2?
To help answer this question, we can conduct prior predictive checks, that is, we can simulate quantities of interest from the pure model and priors, without considering any data at all. This allows us to check if different priors make sense, by looking at simulated quantities of interest with more intuitive interpretations than raw coefficients. We can then refine the model purely based on our prior knowledge, before we let our views be influenced by the observed data.
To conduct a prior predictive check in R, we begin by using the brm() function and its formula syntax to define the model structure, with fixed and random parameters. Then, we set family=bernoulli to specify a logistic regression model. The prior argument is used to specify the priors we want to use, either diffuse or informative. Finally, we instruct brms to ignore the actual data altogether, and to draw simulations only from priors, by setting the argument sample_prior="only".
model_vague=brm(defund~age+education+military+gender+(1+gender|state), family =bernoulli, prior =priors_vague, sample_prior ="only", data =survey)model_informative=brm(defund~age+education+military+gender+(1+gender|state), family =bernoulli, prior =priors_informative, sample_prior ="only", data =survey)
The sample_prior argument is powerful. It allows us to draw simulated coefficients from the model and priors, without looking at the data. But one problem remains: the outputs of this function are still expressed on the same unintuitive scale as the model parameters.
How can we know if the results printed above make sense? One simple approach is to post-process the prior-only brms model using marginaleffects. With this strategy, we can compute any of the quantities of interest introduced earlier in this book: predictions, counterfactual comparisons, and slopes.6
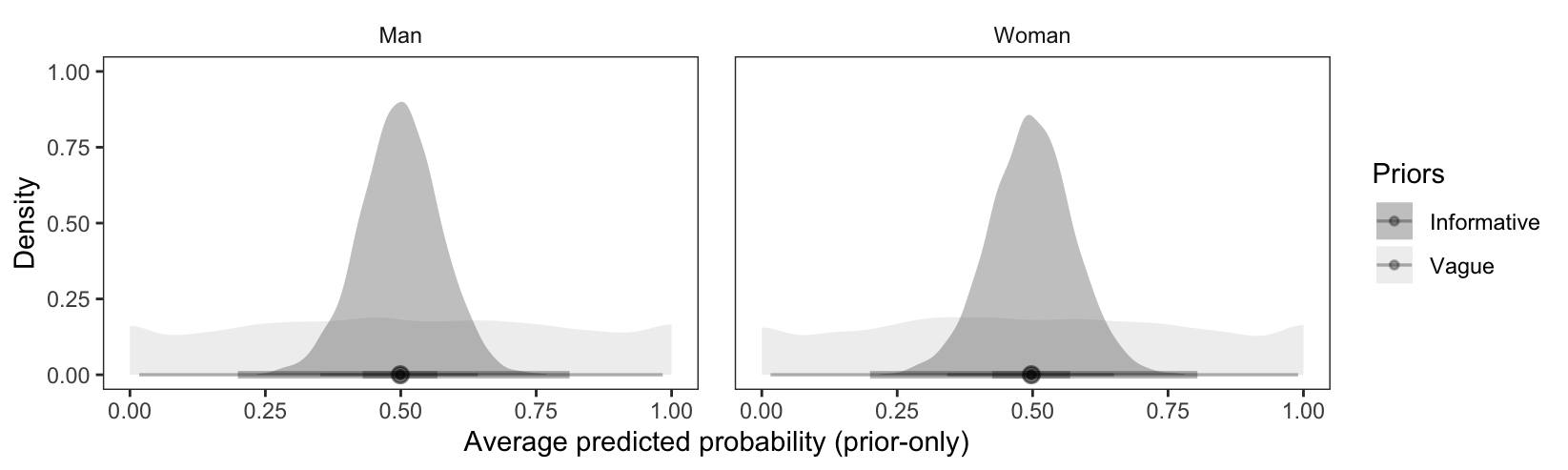
When using vague normal priors, the average predicted probability of supporting cuts to police budgets is centered at 0.5, with credible intervals that cover nearly the full unit interval.
Unsurprisingly, the intervals are much narrower when we use informative priors.
p_informative=avg_predictions(model_informative, by ="gender")p_informative
gender
Estimate
2.5 %
97.5 %
Man
0.502
0.355
0.652
Woman
0.501
0.346
0.651
We can also plot the prior distribution of average predictions. First, we extract draws from both models using get_draws(). Then, we plot them using the ggplot2 and ggdist packages.
draws=rbind(get_draws(p_vague, shape ="rvar"),get_draws(p_informative, shape ="rvar"))draws$Priors=c("Vague", "Vague", "Informative", "Informative")ggplot(draws, aes(xdist =rvar, fill =Priors))+stat_slabinterval(alpha =.5)+facet_wrap(~gender)+scale_fill_grey()+labs(x ="Average predicted probability (prior-only)", y ="Density")
Figure 12.1: Average predictions with vague and informative priors (no data).
If the ultimate goal of our analysis is to compute an average treatment effect via G-computation,7 we can conduct a prior predictive check directly on that quantity. Once again, the intervals are much wider when using vague priors.
We now fit the model to data by dropping the sample_prior argument.
model=brm(defund~age+education+military+gender+(1+gender|state), family =bernoulli, prior =priors_vague, data =survey)
Using this fitted model, we can consider the average predicted probability that a respondent answers “yes” on the defund question, for respondents with or without military experience. By default, marginaleffects functions report the mean of posterior draws, along with equal-tailed intervals.
On average, people who were never in the military have a 44.7% chance of supporting cuts to police budgets. In contrast, survey respondents with military backgrounds have, on average, an estimated probability of 36.4% of answering “yes.”
As in Chapter 6, we can use the avg_comparisons() function to assess the strength of association between some covariate, like age, and the outcome defund.
On average, holding all other variables constant at their observed values, moving from the 18-29 to the 70+ age categories would be associated with a decrease of -31 percentage points in the probability of supporting funding cuts.
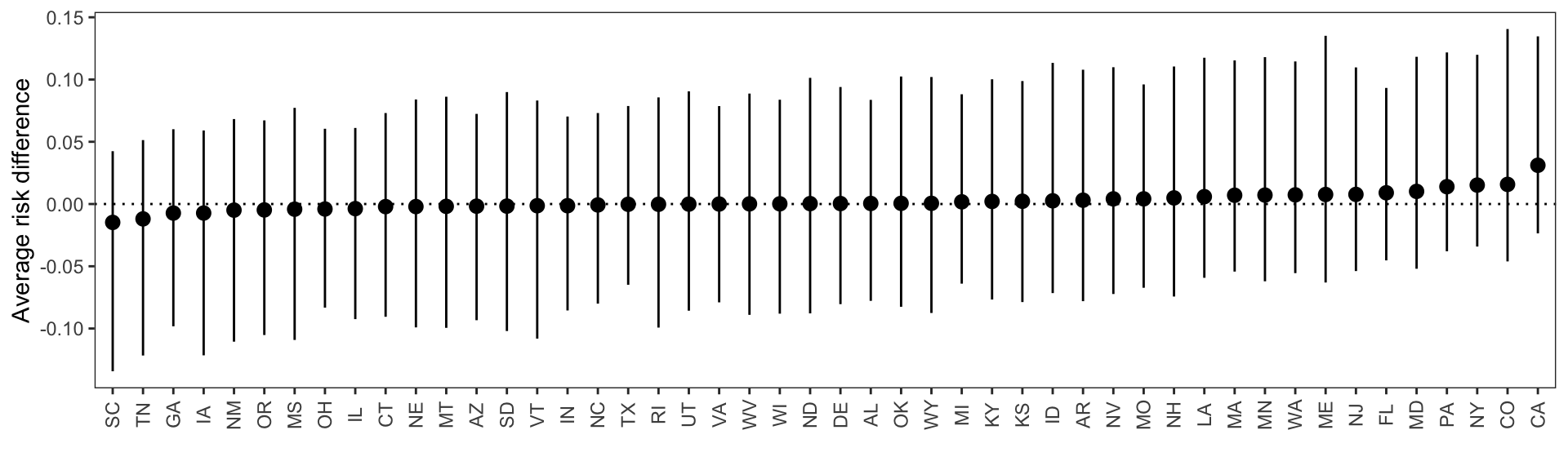
Recall that our model specification allows the parameter associated to gender to vary from state to state. To see if this is the case, we call the comparisons() function with the newdata argument. This computes risk differences for one individual per state, whose characteristics are set to the average or mode of the predictors.
Figure 12.2: Average risk difference for a hypothetical individual with typical characteristics living in different states.
The results in Figure 12.2 show that the estimated risk difference is quite small, hovering around 4 percentage points. The plot also shows that the estimated association between gender and defund is quite stable across states.
When post-processing Bayesian results, it is often useful to directly manipulate draws from the posterior distribution. To extract these draws, we use the get_draws() function. This function can return several types of objects, including data frames in “wide” or “long” formats, matrices, or an rvar distribution object compatible with the posterior package. For instance, we can print the first 5 draws from the posterior distribution of average predictions with it.
This allows us to compute various posterior summaries using standard R functions. The following code shows that about 71% of the posterior density of the average prediction lies above 0.4.
The sample that we used so far is relatively large: 3000 observations. But even if those observations were drawn randomly from the national population, they may still be insufficient to estimate state-level opinion. Indeed, some states are much more populous than others, and our dataset includes very few observations from certain areas of the country.
ND WY SD VT MS ID MT NE NH RI DE AR KS ME WV NM OK IA NV UT
4 5 8 9 12 14 14 15 15 15 19 21 21 21 21 22 23 32 32 33
KY CT LA MN OR AL MD MA WA CO SC WI TN IN MO AZ NJ GA VA NC
40 42 44 44 46 47 49 53 57 59 60 67 70 76 76 81 88 90 90 91
MI IL OH PA NY FL TX CA
94 107 136 144 180 224 224 265
This kind of disparity occurs in many contexts, such as when one estimates quantities like
Presidential voting intentions in swing states, based on a national survey.
Psychological well-being of a population, using a web-based survey that oversamples young and highly-educated people.
Effect of a user interface change on website sales, based on an unbalanced sample of laptop or smartphone users.
Vaccination rates using data from healthcare providers who are overrepresented in affluent neighborhoods.
To draw state-level inferences about defund, we will use the MRP approach, or multilevel regression with poststratification. MRP is implemented in four steps.
First, we estimate a mixed-effects model with random intercept by state. As Ornstein (2023) notes, the accuracy of MRP estimates depends on the predictive performance of this first-stage model, and may be affected by standard problems such as overfitting. Since we have already estimated such a model for previous examples, we simply use the same brms object as before: model.
Second, we must construct a poststratification frame, that is, a dataset that contains information about the prevalence of each possible predictor profile. Typically, the frame is constructed using a canonical source, such as the census. In our case, the demographics poststratification frame records the prevalence of socio-demographic characteristics for each state.8
state age education gender military percent
1 AL 18-29 No HS Man 0 0.3181336
2 AL 18-29 No HS Man 1 0.2120891
3 AL 18-29 No HS Woman 0 0.5302227
4 AL 18-29 No HS Woman 1 0.3181336
5 AL 18-29 High school Man 0 1.8027572
6 AL 18-29 High school Man 1 0.6362672
This table shows, for example, that about 0.318% of the Alabama population are men between the ages of 18 and 29, with no high school degree, and no military experience. Note that the proportions of predictor profiles must sum to one for each state.
The third step in MRP is to make predictions for each row of the poststratification frame. In other words, we use the demographics data frame in newdata, instead of using the empirical grid.
Finally, we take a weighted average of these predictions by state, where weights are defined as the proportion of each demographic group in the state’s population. To do this with marginaleffects, we modify the call above, specifying weights with the wts argument, and the aggregation unit with the by argument.
p=avg_predictions(model, newdata =demographics, wts ="percent", by ="state")head(p)
state
Estimate
2.5 %
97.5 %
AL
0.409
0.355
0.464
AR
0.399
0.348
0.470
AZ
0.382
0.334
0.430
CA
0.450
0.413
0.504
CO
0.437
0.397
0.504
CT
0.402
0.349
0.456
This command gives us one estimate per state. After adjusting for the demographic composition of the state of Alabama, our model estimates that the average probability of supporting cuts to police budgets is 40.9%, with a 95% credible interval of [35.5, 46.4].
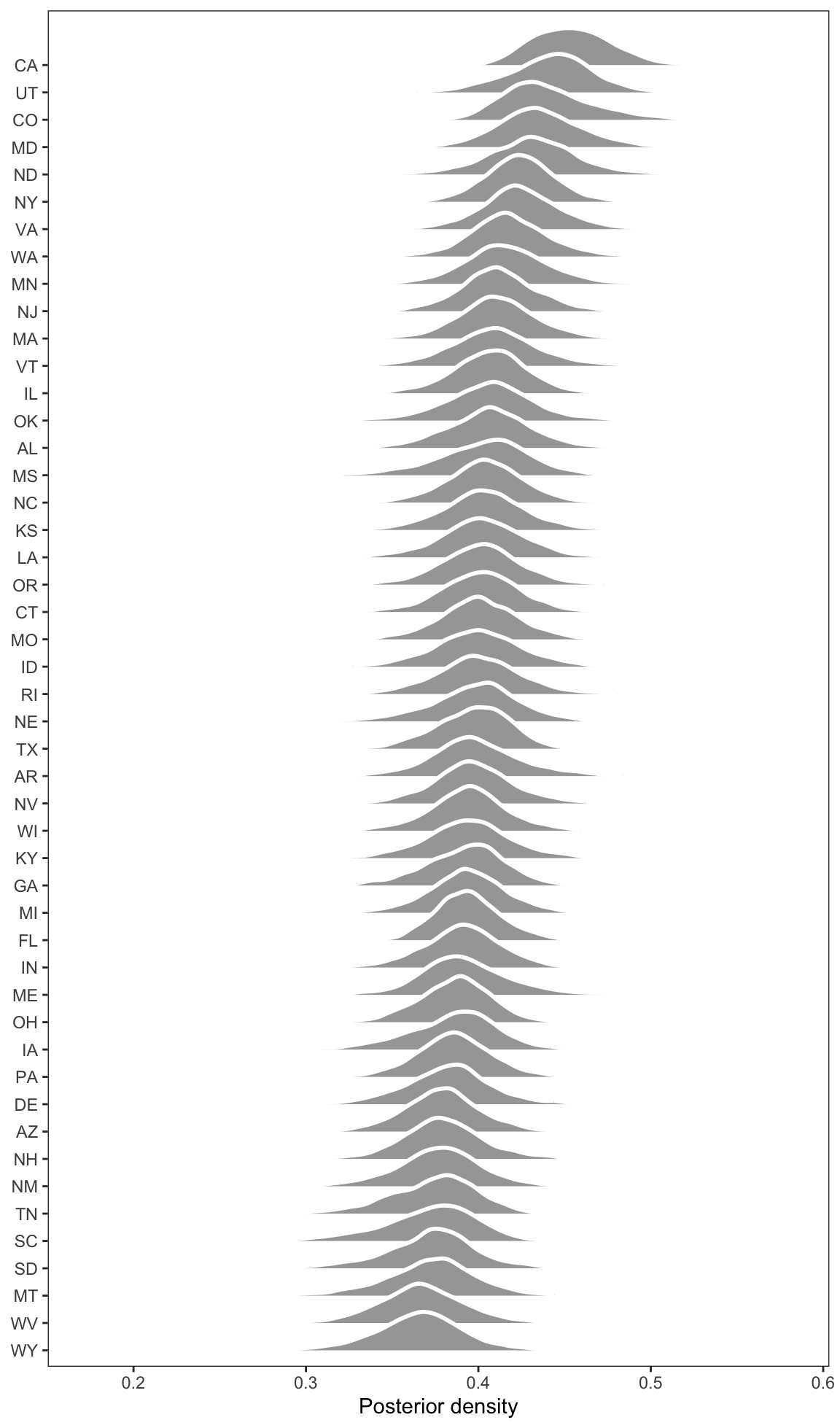
To visualize these results, we can extract draws from the posterior distribution using the get_draws() function, and use the ggdist package to plot densities. Figure 12.3 shows that the support for cuts to police budgets varies across states, with highest estimates in California and lower estimates in Wyoming.
Figure 12.3: Estimated average probability of supporting cuts to police budgets, for each US state. Estimates obtained via Bayesian multilevel regression and poststratification.
In this chapter, we explored the use of multilevel regression with poststratification (MRP) to analyze hierarchical data and draw inferences from unrepresentative samples. We demonstrated how to fit mixed effects models using both frequentist and Bayesian approaches, and how to interpret these models using the marginaleffects package. The chapter highlighted the importance of prior predictive checks in Bayesian analysis and illustrated the process of poststratification to adjust for demographic composition.
Bates, Douglas, Martin Mächler, Ben Bolker, and Steve Walker. 2015. “Fitting Linear Mixed-Effects Models Using lme4.”Journal of Statistical Software 67 (1): 1–48. https://doi.org/10.18637/jss.v067.i01.
Brooks, Mollie E., Kasper Kristensen, Koen J. van Benthem, et al. 2017. “glmmTMB Balances Speed and Flexibility Among Packages for Zero-Inflated Generalized Linear Mixed Modeling.”The R Journal 9 (2): 378–400. https://doi.org/10.32614/RJ-2017-066.
Finch, W Holmes, Jocelyn E Bolin, and Ken Kelley. 2019. Multilevel Modeling Using r. Chapman; Hall/CRC.
Gelman, Andrew, John B. Carlin, Hal S. Stern, David B. Dunson, Aki Vehtari, and Donald B. Rubin. 2013. Bayesian Data Analysis. 3rd ed. Chapman; Hall/CRC. https://doi.org/10.1201/b16018.
Gelman, Andrew, and Jennifer Hill. 2006. Data Analysis Using Regression and Multilevel/Hierarchical Models. 1st ed. Cambridge University Press. http://www.stat.columbia.edu/~gelman/arm/.
Hodges, James S. 2021. Richly Parameterized Linear Models: Additive, Time Series, and Spatial Models Using Random Effects. 1st ed. Chapman & Hall.
McElreath, Richard. 2020. Statistical Rethinking: A Bayesian Course with Examples in r and STAN. 2nd ed. Chapman; Hall/CRC. https://doi.org/10.1201/9780429029608.
Ornstein, Joseph T. 2023. “Getting the Most Out of Surveys: Multilevel Regression and Poststratification.” In Causality in Policy Studies: A Pluralist Toolbox, edited by Alessia Damonte and Fedra Negri. Springer. https://doi.org/10.1007/978-3-031-12982-7_5.
This case study only includes code for R. The features illustrated here are on the roadmap for Python but, at the time of writing, were not supported yet.↩︎
The survey firm asked respondents if they supported or opposed this policy: “Decrease the number of police on the street by 10 percent, and increase funding for other public services.”↩︎
Note that the uncertainty estimates reported by marginaleffects for frequentist mixed effects models only take into account the variability in fixed effects parameters, and not in random effects parameters. Bayesian modeling allows for more options in the quantification of uncertainty.↩︎
A comprehensive treatment of Bayesian modeling would obviously require more space than this short chapter affords. Interested readers can refer to many recent texts, such as Gelman et al. (2013), McElreath (2020), or Bürkner (2024).↩︎
Ideally, the demographics data frame would be “complete,” in the sense that it would record the prevalence of every possible type of individual, in every state. Unfortunately, this is not always possible, when demographic information is not available for certain subsets of the population, for example in narrow groups, in less populous states.↩︎