
Slopes
Definition and motivation
Slopes are defined as:
Partial derivatives of the regression equation with respect to a regressor of interest. a.k.a. Marginal effects, trends, velocity.
In some disciplines, like economics and political science, slopes are called “marginal effects,” where marginal refers to the idea of a “small change,” in the calculus sense. In other disciplines, they are called “trends” or “velocity.” In this vignette, we use these terms interchageably.
A slope measures the association between a change in a regressor \(x\), and a change in the response \(y\), estimated at a specific values of the regressor \(x\). Slopes are extremely useful, because they are intuitive and easy to interpret. They are often the main quantity of interest in an empirical analysis.
In scientific practice, slopes fall in the same toolbox as the “Contrast.” Both try to answer a counterfactual question: What would happen to \(y\) if \(x\) were different? They allow us to model the “effect” of a change in the explanator \(x\) on the response \(y\).1
To illustrate the concept, consider this quadratic function:
\[y = -x^2\]
From the definition above, we know that the marginal effect is the partial derivative of \(y\) with respect to \(x\):
\[\frac{\partial y}{\partial x} = -2x\]
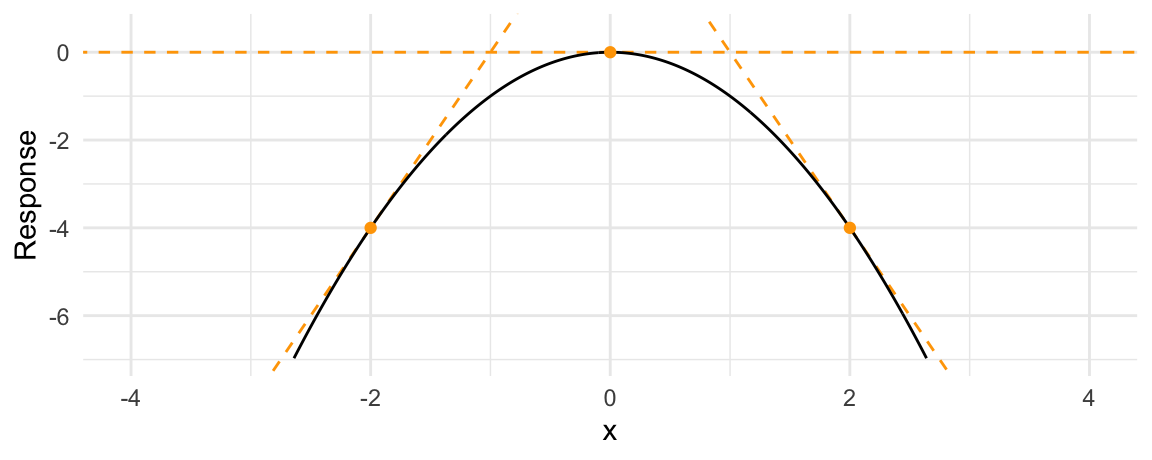
To get intuition about how to interpret this quantity, consider the response of \(y\) to \(x\). It looks like this:
When \(x\) increases, \(y\) starts to increase. But then, as \(x\) increases further, \(y\) creeps back down in negative territory.
A marginal effect is the slope of this response function at a certain value of \(x\). The next plot adds three tangent lines, highlighting the slopes of the response function for three values of \(x\). The slopes of these tangents tell us three things:
- When \(x<0\), the slope is positive: an increase in \(x\) is associated with an increase in \(y\): The marginal effect is positive.
- When \(x=0\), the slope is null: a (small) change in \(x\) is associated with no change in \(y\). The marginal effect is null.
- When \(x>0\), the slope is negative: an increase in \(x\) is associated with a decrease in \(y\). The marginal effect is negative.
Above, we considered how marginal effects can be computed analytically in a simple quadratic equation context. We can now use the slopes function to replicate our analysis of the quadratic function in a regression application.
Say you estimate a linear regression model with a quadratic term:
\[Y = \beta_0 + \beta_1 X^2 + \varepsilon\]
and obtain estimates of \(\beta_0=1\) and \(\beta_1=2\). Taking the partial derivative with respect to \(X\) and plugging in our estimates gives us the marginal effect of \(X\) on \(Y\):
\[\partial Y / \partial X = \beta_0 + 2 \cdot \beta_1 X\] \[\partial Y / \partial X = 1 + 4X\]
This result suggests that the effect of a change in \(X\) on \(Y\) depends on the level of \(X\). When \(X\) is large and positive, an increase in \(X\) is associated to a large increase in \(Y\). When \(X\) is small and positive, an increase in \(X\) is associated to a small increase in \(Y\). When \(X\) is a large negative value, an increase in \(X\) is associated with a decrease in \(Y\).
marginaleffects arrives at the same conclusion in simulated data:
library(tidyverse)
N <- 1e5
quad <- data.frame(x = rnorm(N))
quad$y <- 1 + 1 * quad$x + 2 * quad$x^2 + rnorm(N)
mod_quad <- lm(y ~ x + I(x^2), quad)
slopes(mod_quad, newdata = datagrid(x = -2:2)) |>
mutate(truth = 1 + 4 * x) |>
select(estimate, truth)
#>
#> Estimate
#> -6.986
#> -2.993
#> 0.999
#> 4.992
#> 8.984
#>
#> Columns: estimate, truthWe can plot conditional adjusted predictions with plot_predictions function:
plot_predictions(mod_quad, condition = "x")
We can plot conditional marginal effects with the plot_slopes function (see section below):
plot_slopes(mod_quad, variables = "x", condition = "x")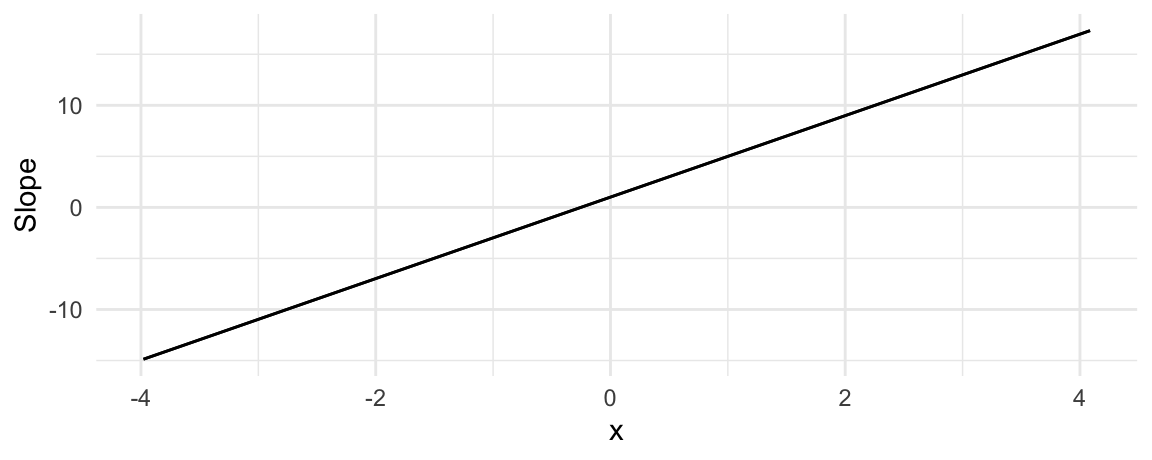
Again, the conclusion is the same. When \(x<0\), an increase in \(x\) is associated with an decrease in \(y\). When \(x>1/4\), the marginal effect is positive, which suggests that an increase in \(x\) is associated with an increase in \(y\).
Slopes are unit-level measures of association between changes in a regressor and changes in the response. Except in the simplest linear models, the value of the marginal effect will be different from individual to individual, because it will depend on the values of the other covariates for each individual.
By default, the slopes() function thus produces distinct estimates of the marginal effect for each row of the data used to fit the model:
mfx <- slopes(mod_quad)
dim(mfx)
#> [1] 100000 14
head(mfx)
#>
#> Term Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
#> x 7.900 0.00843 938 <0.001 Inf 7.884 7.917
#> x 1.185 0.00318 373 <0.001 Inf 1.179 1.192
#> x -2.778 0.00531 -523 <0.001 Inf -2.788 -2.768
#> x -0.435 0.00355 -122 <0.001 Inf -0.442 -0.428
#> x -0.603 0.00364 -165 <0.001 Inf -0.610 -0.596
#> x -0.800 0.00376 -213 <0.001 Inf -0.807 -0.792
#>
#> Columns: rowid, term, estimate, std.error, statistic, p.value, s.value, conf.low, conf.high, predicted_lo, predicted_hi, predicted, y, x
#> Type: response
mfx
#>
#> Term Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
#> x 7.900 0.00843 938 <0.001 Inf 7.884 7.917
#> x 1.185 0.00318 373 <0.001 Inf 1.179 1.192
#> x -2.778 0.00531 -523 <0.001 Inf -2.788 -2.768
#> x -0.435 0.00355 -122 <0.001 Inf -0.442 -0.428
#> x -0.603 0.00364 -165 <0.001 Inf -0.610 -0.596
#> --- 99990 rows omitted. See ?avg_slopes and ?print.marginaleffects ---
#> x -3.161 0.00566 -559 <0.001 Inf -3.172 -3.150
#> x 0.836 0.00317 263 <0.001 Inf 0.830 0.842
#> x 1.914 0.00334 574 <0.001 Inf 1.907 1.921
#> x 4.810 0.00535 898 <0.001 Inf 4.800 4.821
#> x 5.150 0.00567 908 <0.001 Inf 5.139 5.161
#> Columns: rowid, term, estimate, std.error, statistic, p.value, s.value, conf.low, conf.high, predicted_lo, predicted_hi, predicted, y, x
#> Type: responseThe Marginal Effects Zoo
Analysts often use the term “marginal effects” to refer to slopes. And since slopes are conditional unit-level quantities, they can be aggregated and reported in various ways. This gave rise to nomenclature that can be confusion to newcomers.
In this section, we show how the conceptual framework introduced in the “Get Started”, the “Predictions”, and the “Comparisons” vignettes can help us understand these different quantities. Throughout, we lean on the five pillars:
- Quantity of interest
- Grid
- Aggregation
- Uncertainty
- Test
This allows us to understand various estimates described in Andrew Heiss’ characteristically excellent blog post::
- Average Marginal Effects
- Group-Average Marginal Effects
- Marginal Effects at User-Specified Values (or Representative Values)
- Marginal Effects at the Mean
- Counterfactual Marginal Effects
- Conditional Marginal Effects

Throughout this section, we will illustrate various concepts using a logistic regression model fit on data from the Palmer Penguins dataset:
library(marginaleffects)
dat <- read.csv("https://vincentarelbundock.github.io/Rdatasets/csv/palmerpenguins/penguins.csv")
dat$large_penguin <- ifelse(dat$body_mass_g > median(dat$body_mass_g, na.rm = TRUE), 1, 0)
mod <- glm(large_penguin ~ bill_length_mm * flipper_length_mm + species,
data = dat, family = binomial)Average Marginal Effect (AME)
A dataset with one marginal effect estimate per unit of observation is a bit unwieldy and difficult to interpret. Many analysts like to report the “Average Marginal Effect”, that is, the average of all the observation-specific marginal effects. These are easy to compute based on the full data.frame shown above, but the avg_slopes() function is convenient:
avg_slopes(mod)
#>
#> Term Contrast Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
#> bill_length_mm mean(dY/dX) 0.0279 0.00595 4.685 <0.001 18.4 0.01620 0.0395
#> flipper_length_mm mean(dY/dX) 0.0105 0.00237 4.426 <0.001 16.7 0.00585 0.0151
#> species mean(Chinstrap) - mean(Adelie) -0.4128 0.05600 -7.371 <0.001 42.4 -0.52255 -0.3030
#> species mean(Gentoo) - mean(Adelie) 0.0609 0.10734 0.568 0.57 0.8 -0.14946 0.2713
#>
#> Columns: term, contrast, estimate, std.error, statistic, p.value, s.value, conf.low, conf.high, predicted_lo, predicted_hi, predicted
#> Type: responseNote that since marginal effects are derivatives, they are only properly defined for continuous numeric variables. When the model also includes categorical regressors, the summary function will try to display relevant (regression-adjusted) contrasts between different categories, as shown above.
Group-Average Marginal Effect (G-AME)
We can also use the by argument the average marginal effects within different subgroups of the observed data, based on values of the regressors. For example, to compute the average marginal effects of Bill Length for each Species, we do:
mfx <- avg_slopes(
mod,
by = "species",
variables = "bill_length_mm")
mfx
#>
#> Term Contrast species Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
#> bill_length_mm mean(dY/dX) Adelie 0.04392 0.00904 4.860 <0.001 19.7 0.02620 0.0616
#> bill_length_mm mean(dY/dX) Chinstrap 0.03704 0.00970 3.818 <0.001 12.9 0.01803 0.0561
#> bill_length_mm mean(dY/dX) Gentoo 0.00307 0.00313 0.981 0.327 1.6 -0.00306 0.0092
#>
#> Columns: term, contrast, species, estimate, std.error, statistic, p.value, s.value, conf.low, conf.high, predicted_lo, predicted_hi, predicted
#> Type: responseThis is equivalent to manually taking the mean of the observation-level marginal effect for each species sub-group:
Note that marginaleffects follows Stata and the margins package in computing standard errors using the group-wise averaged Jacobian.
Marginal Effect at User-Specified Values
Sometimes, we are not interested in all the unit-specific marginal effects, but would rather look at the estimated marginal effects for certain “typical” individuals, or for user-specified values of the regressors. The datagrid function helps us build a data grid full of “typical” rows. For example, to generate artificial Adelies and Gentoos with 180mm flippers:
The same command can be used (omitting the model argument) to marginaleffects’s newdata argument to compute marginal effects for those (fictional) individuals:
slopes(
mod,
newdata = datagrid(
flipper_length_mm = 180,
species = c("Adelie", "Gentoo")))
#>
#> Term Contrast flipper_length_mm species Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
#> bill_length_mm dY/dX 180 Adelie 0.0578 0.03496 1.652 0.0986 3.3 -0.01078 1.26e-01
#> bill_length_mm dY/dX 180 Gentoo 0.0804 0.04314 1.863 0.0624 4.0 -0.00417 1.65e-01
#> flipper_length_mm dY/dX 180 Adelie 0.0233 0.00555 4.191 <0.001 15.1 0.01238 3.41e-02
#> flipper_length_mm dY/dX 180 Gentoo 0.0324 0.00880 3.678 <0.001 12.1 0.01512 4.96e-02
#> species Chinstrap - Adelie 180 Adelie -0.2106 0.10748 -1.959 0.0501 4.3 -0.42121 9.48e-05
#> species Chinstrap - Adelie 180 Gentoo -0.2106 0.10748 -1.959 0.0501 4.3 -0.42121 9.48e-05
#> species Gentoo - Adelie 180 Adelie 0.1556 0.30082 0.517 0.6051 0.7 -0.43403 7.45e-01
#> species Gentoo - Adelie 180 Gentoo 0.1556 0.30082 0.517 0.6051 0.7 -0.43403 7.45e-01
#>
#> Columns: rowid, term, contrast, estimate, std.error, statistic, p.value, s.value, conf.low, conf.high, flipper_length_mm, species, predicted_lo, predicted_hi, predicted, bill_length_mm, large_penguin
#> Type: responseWhen variables are omitted from the datagrid call, they will automatically be set at their mean or mode (depending on variable type).
Marginal Effect at the Mean (MEM)
The “Marginal Effect at the Mean” is a marginal effect calculated for a hypothetical observation where each regressor is set at its mean or mode. By default, the datagrid function that we used in the previous section sets all regressors to their means or modes. To calculate the MEM, we can set the newdata argument, which determines the values of predictors at which we want to compute marginal effects:
slopes(mod, newdata = "mean")
#>
#> Term Contrast Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
#> bill_length_mm dY/dX 0.0519 0.01449 3.581 <0.001 11.5 0.02348 0.0803
#> flipper_length_mm dY/dX 0.0193 0.00558 3.464 <0.001 10.9 0.00839 0.0303
#> species Chinstrap - Adelie -0.8088 0.07663 -10.554 <0.001 84.1 -0.95897 -0.6586
#> species Gentoo - Adelie 0.0818 0.11540 0.709 0.478 1.1 -0.14435 0.3080
#>
#> Columns: rowid, term, contrast, estimate, std.error, statistic, p.value, s.value, conf.low, conf.high, predicted_lo, predicted_hi, predicted, bill_length_mm, flipper_length_mm, species, large_penguin
#> Type: responseCounterfactual Marginal Effects
The datagrid function allowed us look at completely fictional individuals. Setting the grid_type argument of this function to "counterfactual" lets us compute the marginal effects for the actual observations in our dataset, but with a few manipulated values. For example, this code will create a data.frame twice as long as the original dat, where each observation is repeated with different values of the flipper_length_mm variable:
We see that the rows 1, 2, and 3 of the original dataset have been replicated twice, with different values of the flipper_length_mm variable:
nd[nd$rowid %in% 1:3,]
#> rowidcf large_penguin bill_length_mm species flipper_length_mm
#> 1 1 0 39.1 Adelie 160
#> 2 2 0 39.5 Adelie 160
#> 3 3 0 40.3 Adelie 160
#> 343 1 0 39.1 Adelie 180
#> 344 2 0 39.5 Adelie 180
#> 345 3 0 40.3 Adelie 180We can use the observation-level marginal effects to compute average (or median, or anything else) marginal effects over the counterfactual individuals:
Conditional Marginal Effects (Plot)
The plot_slopes function can be used to draw “Conditional Marginal Effects.” This is useful when a model includes interaction terms and we want to plot how the marginal effect of a variable changes as the value of a “condition” (or “moderator”) variable changes:
mod <- lm(mpg ~ hp * wt + drat, data = mtcars)
plot_slopes(mod, variables = "hp", condition = "wt")
The marginal effects in the plot above were computed with values of all regressors – except the variables and the condition – held at their means or modes, depending on variable type.
Since plot_slopes() produces a ggplot2 object, it is easy to customize. For example:
plot_slopes(mod, variables = "hp", condition = "wt") +
geom_rug(aes(x = wt), data = mtcars) +
theme_classic()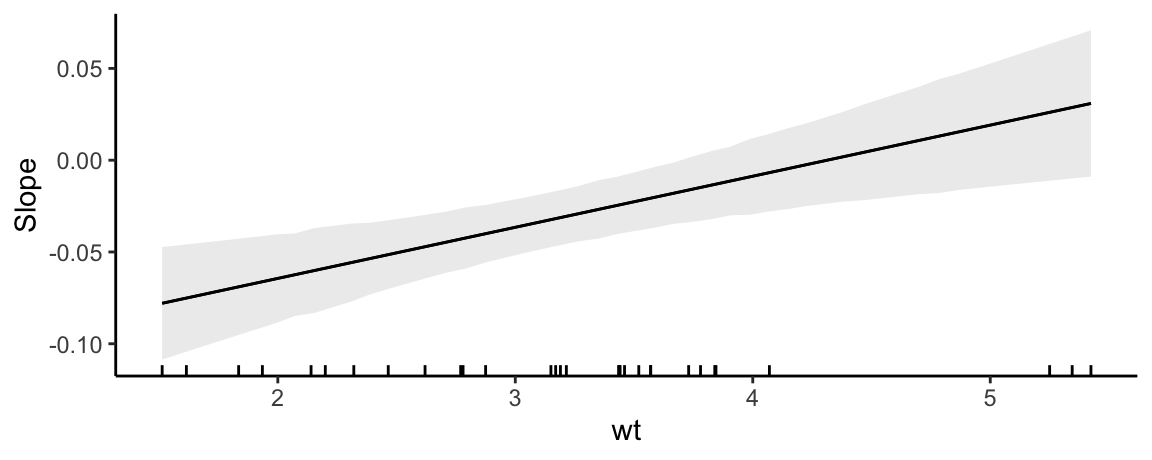
Slopes vs Predictions: A Visual Interpretation
Often, analysts will plot predicted values of the outcome with a best fit line:
library(ggplot2)
mod <- lm(mpg ~ hp * qsec, data = mtcars)
plot_predictions(mod, condition = "hp", vcov = TRUE) +
geom_point(data = mtcars, aes(hp, mpg)) 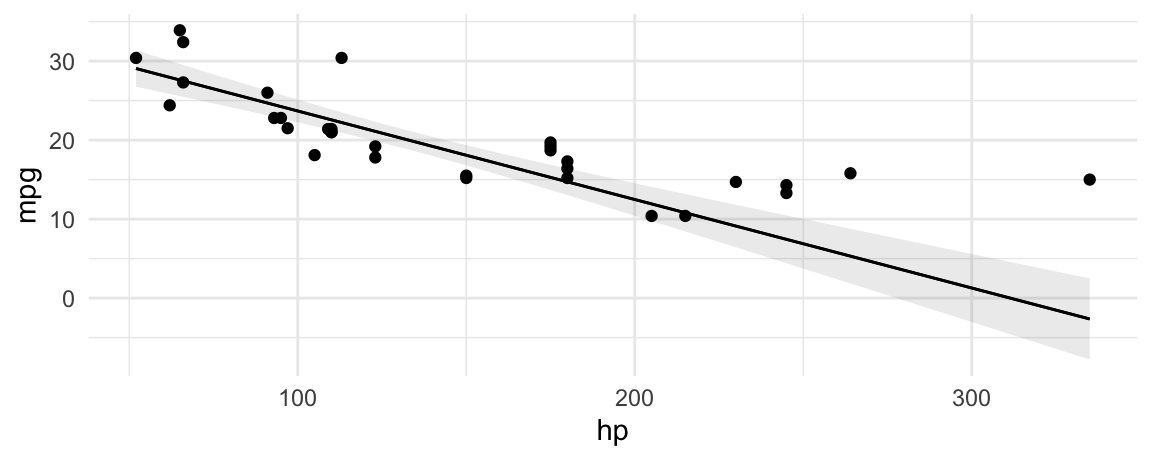
The slope of this line is calculated using the same technique we all learned in grade school: dividing rise over run.
p <- plot_predictions(mod, condition = "hp", vcov = TRUE, draw = FALSE)
plot_predictions(mod, condition = "hp", vcov = TRUE) +
geom_segment(aes(x = p$hp[10], xend = p$hp[10], y = p$estimate[10], yend = p$estimate[20])) +
geom_segment(aes(x = p$hp[10], xend = p$hp[20], y = p$estimate[20], yend = p$estimate[20])) +
annotate("text", label = "Rise", y = 10, x = 140) +
annotate("text", label = "Run", y = 2, x = 200)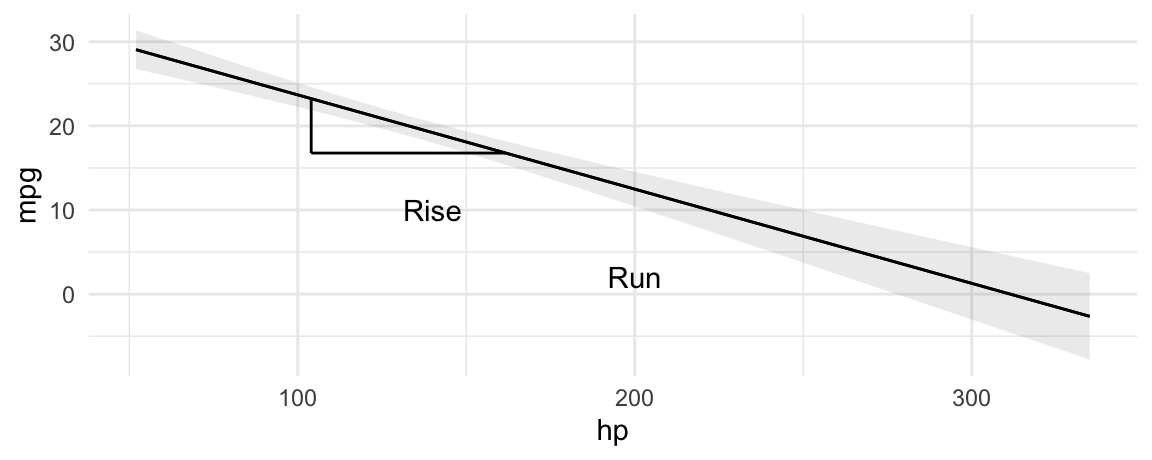
Instead of computing this slope manually, we can just call:
avg_slopes(mod, variables = "hp")
#>
#> Term Contrast Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
#> hp mean(dY/dX) -0.112 0.0126 -8.92 <0.001 61.0 -0.137 -0.0874
#>
#> Columns: term, contrast, estimate, std.error, statistic, p.value, s.value, conf.low, conf.high, predicted_lo, predicted_hi, predicted
#> Type: responseNow, consider the fact that our model includes an interaction between hp and qsec. This means that the slope will actually differ based on the value of the moderator variable qsec:
plot_predictions(mod, condition = list("hp", "qsec" = "quartile"))
We can estimate the slopes of these three fit lines easily:
slopes(
mod,
variables = "hp",
newdata = datagrid(qsec = quantile(mtcars$qsec, probs = c(.25, .5, .75))))
#>
#> Term qsec Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
#> hp 16.9 -0.0934 0.0111 -8.43 <0.001 54.7 -0.115 -0.0717
#> hp 17.7 -0.1093 0.0123 -8.92 <0.001 60.8 -0.133 -0.0853
#> hp 18.9 -0.1325 0.0154 -8.60 <0.001 56.8 -0.163 -0.1023
#>
#> Columns: rowid, term, estimate, std.error, statistic, p.value, s.value, conf.low, conf.high, qsec, predicted_lo, predicted_hi, predicted, hp, mpg
#> Type: responseAs we see in the graph, all three slopes are negative, but the Q3 slope is steepest.
We could then push this one step further, and measure the slope of mpg with respect to hp, for all observed values of qsec. This is achieved with the plot_slopes() function:
plot_slopes(mod, variables = "hp", condition = "qsec") +
geom_hline(yintercept = 0, linetype = 3)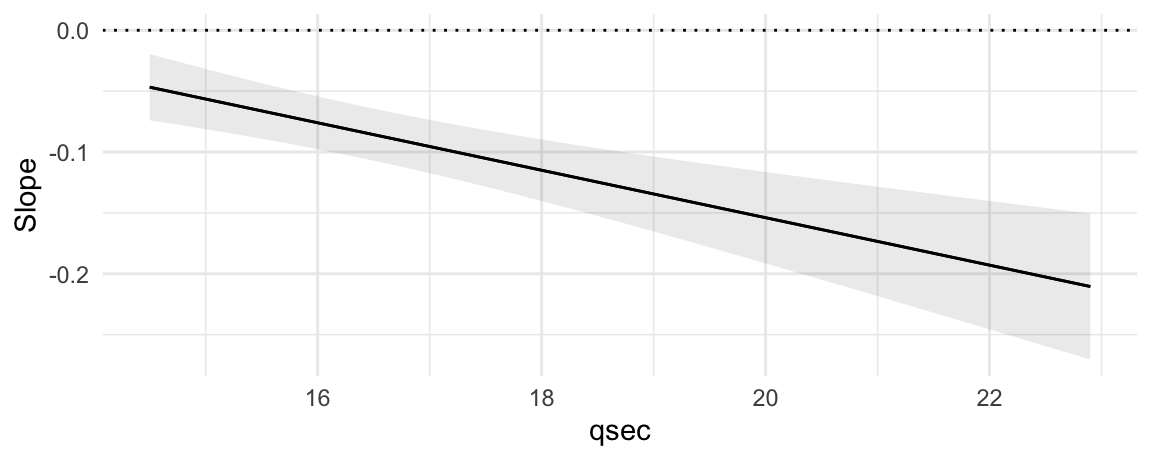
This plot shows that the marginal effect of hp on mpg is always negative (the slope is always below zero), and that this effect becomes even more negative as qsec increases.
Minimum velocity
In some fields such as epidemiology, it is common to compute the minimum or maximum slope, as a measure of the “velocity” of the response function. To achieve this, we can use the comparisons() function and define custom functions. Here, we present a quick example without much detail, but you can refer to the comparisons vignette for more explanations on custom functions in the comparison argument.
Consider this simple GAM model:
library(marginaleffects)
library(itsadug)
library(mgcv)
simdat$Subject <- as.factor(simdat$Subject)
model <- bam(Y ~ Group + s(Time, by = Group) + s(Subject, bs = "re"),
data = simdat)
plot_slopes(model, variables = "Time", condition = c("Time", "Group"))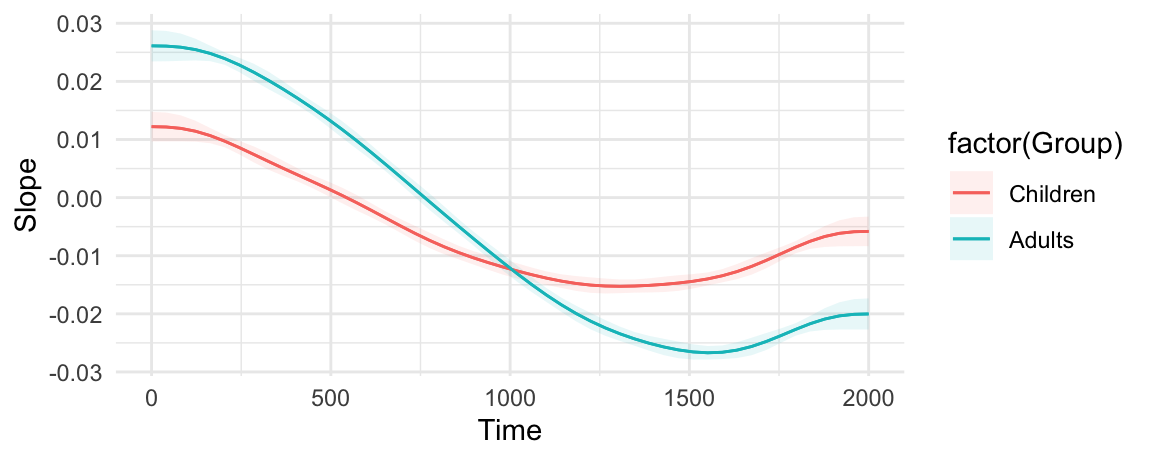
Minimum velocity, overall:
comparisons(model,
variables = list("Time" = 1e-6),
vcov = FALSE,
comparison = \(hi, lo) min((hi - lo) / 1e-6))
#>
#> Term Contrast Estimate
#> Time +1e-06 -0.0267
#>
#> Columns: term, contrast, estimate, predicted_lo, predicted_hi, predicted
#> Type: responseMinimum velocity by group:
comparisons(model,
variables = list("Time" = 1e-6),
by = "Group",
vcov = FALSE,
comparison = \(hi, lo) min((hi - lo) / 1e-6))
#>
#> Term Contrast Group Estimate
#> Time +1e-06 Children -0.0153
#> Time +1e-06 Adults -0.0267
#>
#> Columns: term, contrast, Group, estimate
#> Type: responseDifference between the minimum velocity of each group:
comparisons(model,
variables = list("Time" = 1e-6),
vcov = FALSE,
by = "Group",
hypothesis = "pairwise",
comparison = \(hi, lo) min((hi - lo) / 1e-6))
#>
#> Term Estimate
#> Children - Adults 0.0114
#>
#> Columns: term, estimate
#> Type: responseWhat Time value corresponds to the minimum velocity?
low = function(hi, lo, x) {
dydx <- (hi - lo) / 1e-6
dydx_min <- min(dydx)
x[dydx == dydx_min][1]
}
comparisons(model,
variables = list("Time" = 1e-6),
vcov = FALSE,
by = "Group",
comparison = low)
#>
#> Term Contrast Group Estimate
#> Time +1e-06 Children 1313
#> Time +1e-06 Adults 1556
#>
#> Columns: term, contrast, Group, estimate
#> Type: responseManual computation
Now we illustrate how to reproduce the output of slopes manually:
library(marginaleffects)
mod <- glm(am ~ hp, family = binomial, data = mtcars)
eps <- 1e-4
d1 <- transform(mtcars, hp = hp - eps / 2)
d2 <- transform(mtcars, hp = hp + eps / 2)
p1 <- predict(mod, type = "response", newdata = d1)
p2 <- predict(mod, type = "response", newdata = d2)
s <- (p2 - p1) / eps
tail(s)
#> Porsche 914-2 Lotus Europa Ford Pantera L Ferrari Dino Maserati Bora Volvo 142E
#> -0.0020285496 -0.0020192814 -0.0013143243 -0.0018326764 -0.0008900012 -0.0020233577Which is equivalent to:
slopes(mod, eps = eps) |> tail()
#>
#> Term Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
#> hp -0.00203 0.001347 -1.51 0.13199 2.9 -0.00467 0.000611
#> hp -0.00202 0.001556 -1.30 0.19440 2.4 -0.00507 0.001031
#> hp -0.00131 0.000441 -2.98 0.00285 8.5 -0.00218 -0.000451
#> hp -0.00183 0.001323 -1.39 0.16591 2.6 -0.00443 0.000760
#> hp -0.00089 0.000283 -3.14 0.00169 9.2 -0.00145 -0.000334
#> hp -0.00202 0.001586 -1.28 0.20206 2.3 -0.00513 0.001085
#>
#> Columns: rowid, term, estimate, std.error, statistic, p.value, s.value, conf.low, conf.high, predicted_lo, predicted_hi, predicted, am, hp
#> Type: responseAnd we can get average marginal effects by subgroup as follows:
tapply(s, mtcars$cyl, mean)
#> 4 6 8
#> -0.002010526 -0.001990774 -0.001632681
slopes(mod, eps = eps, by = "cyl")
#>
#> Term Contrast cyl Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
#> hp mean(dY/dX) 4 -0.00201 0.00141 -1.43 0.1540 2.7 -0.00478 0.000754
#> hp mean(dY/dX) 6 -0.00199 0.00150 -1.33 0.1833 2.4 -0.00492 0.000941
#> hp mean(dY/dX) 8 -0.00163 0.00095 -1.72 0.0858 3.5 -0.00350 0.000230
#>
#> Columns: term, contrast, cyl, estimate, std.error, statistic, p.value, s.value, conf.low, conf.high, predicted_lo, predicted_hi, predicted
#> Type: responseFootnotes
The term “effect” is tricky. To be clear, this vignette does not use the word “effect” to imply “causality”.↩︎