Description
Plot predictions on the y-axis against values of one or more predictors (x-axis, colors/shapes, and facets).
The by argument is used to plot marginal predictions, that is, predictions made on the original data, but averaged by subgroups. This is analogous to using the by argument in the predictions() function.
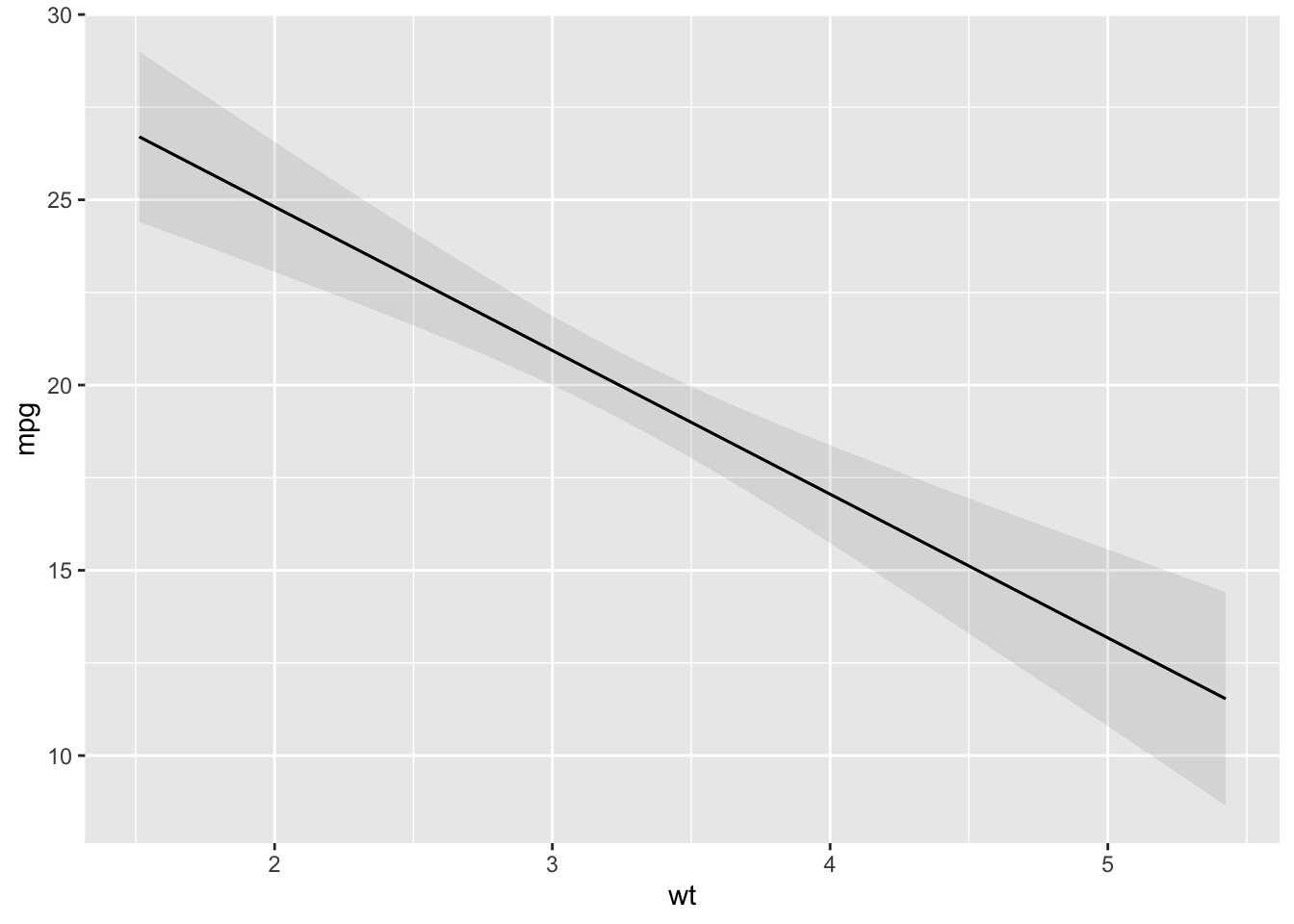
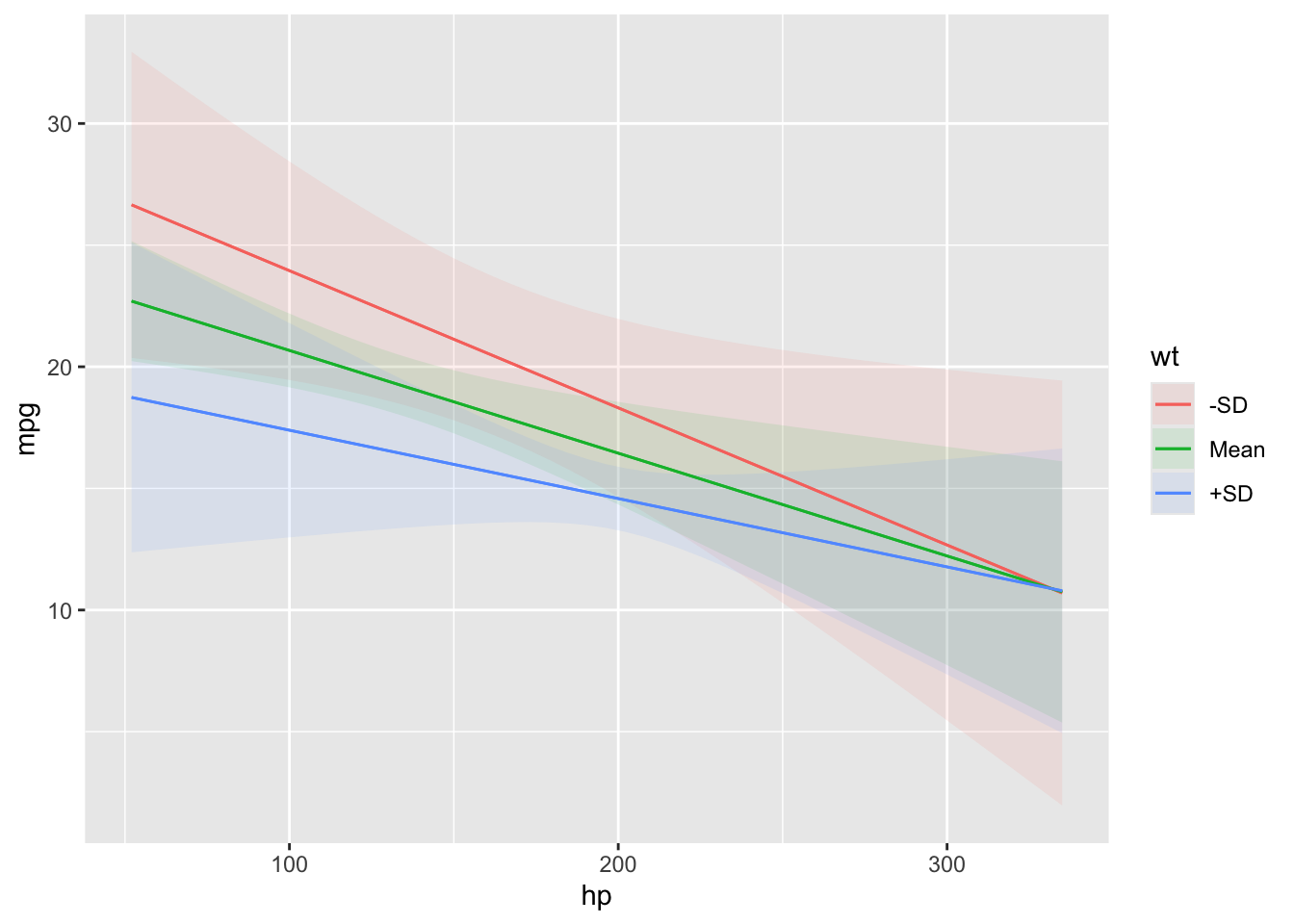
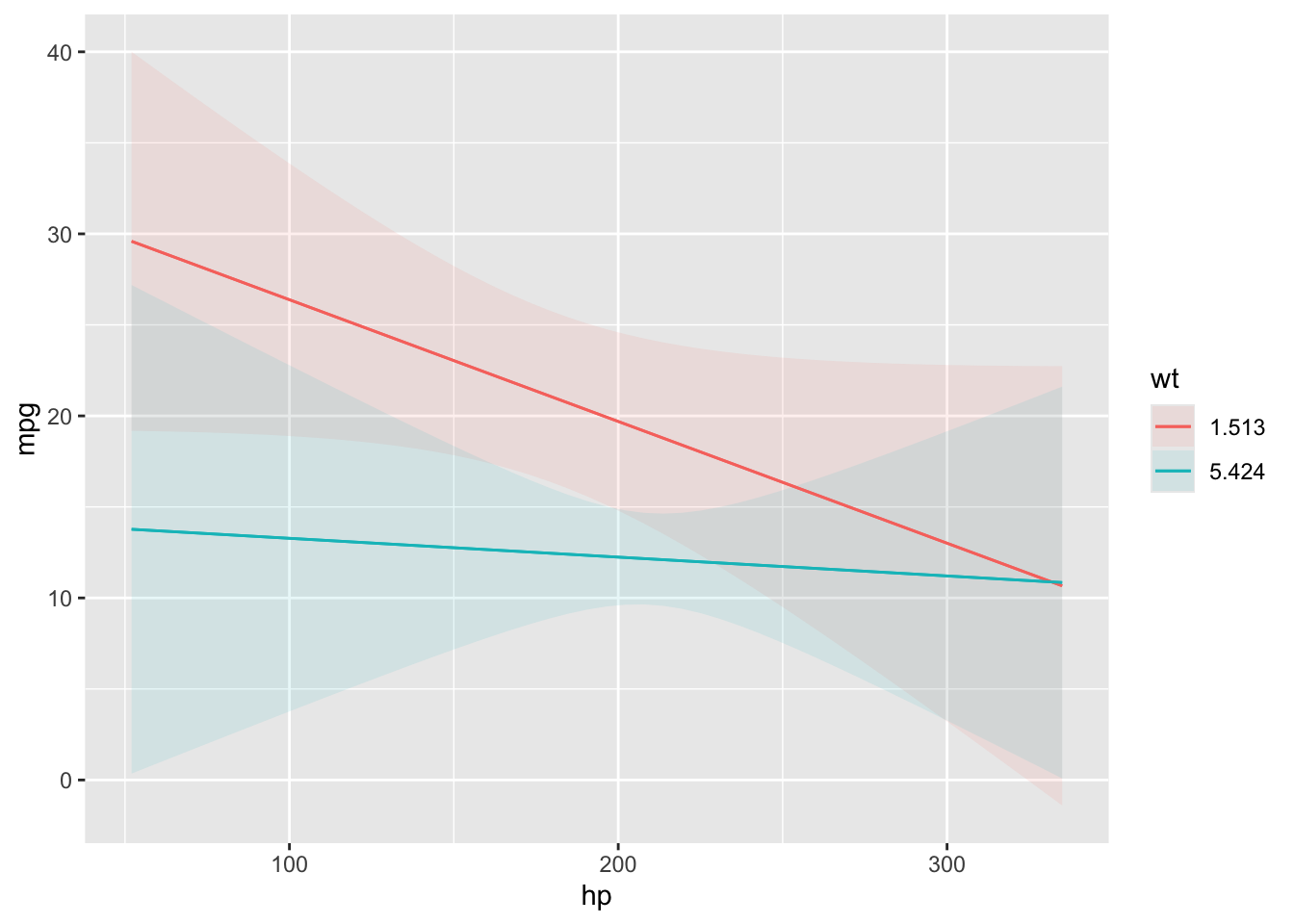
The condition argument is used to plot conditional predictions, that is, predictions made on a user-specified grid. This is analogous to using the newdata argument and datagrid() function in a predictions() call. All variables whose values are not specified explicitly are treated as usual by datagrid(), that is, they are held at their mean or mode (or rounded mean for integers). This includes grouping variables in mixed-effects models, so analysts who fit such models may want to specify the groups of interest using the condition argument, or supply model-specific arguments to compute population-level estimates. See details below.
See the "Plots" vignette and website for tutorials and information on how to customize plots:
Usage
plot_predictions(
model,
condition = NULL,
by = NULL,
newdata = NULL,
type = NULL,
vcov = NULL,
conf_level = 0.95,
wts = FALSE,
transform = NULL,
points = 0,
rug = FALSE,
gray = FALSE,
draw = TRUE,
...
)
Prediction types
The type argument determines the scale of the predictions used to compute quantities of interest with functions from the marginaleffects package. Admissible values for type depend on the model object. When users specify an incorrect value for type, marginaleffects will raise an informative error with a list of valid type values for the specific model object. The first entry in the list in that error message is the default type.
The invlink(link) is a special type defined by marginaleffects. It is available for some (but not all) models and functions. With this link type, we first compute predictions on the link scale, then we use the inverse link function to backtransform the predictions to the response scale. This is useful for models with non-linear link functions as it can ensure that confidence intervals stay within desirable bounds, ex: 0 to 1 for a logit model. Note that an average of estimates with type=“invlink(link)” will not always be equivalent to the average of estimates with type=“response”.
Some of the most common type values are:
response, link, E, Ep, average, class, conditional, count, cum.prob, cumhaz, cumprob, density, detection, disp, ev, expected, expvalue, fitted, hazard, invlink(link), latent, latent_N, linear, linear.predictor, linpred, location, lp, mean, numeric, p, ppd, pr, precision, prediction, prob, probability, probs, quantile, risk, rmst, scale, survival, unconditional, utility, variance, xb, zero, zlink, zprob